So basically I have a dataframe like this
worker_codes Capacity new_codes
[24751454, 24751454] 2 [17425801, 74730846]
where either worker_code and new_codes are two lists with ids and the capacity is the lenght of worker_code. What I would like to have is something like this
list_of_codes capacity
[17425801, 74730846, 24751454] 3
So to merge the two lists removing duplicates and set the new capacity to the lenght of the new list. How can I do it?
CodePudding user response:
You can add lists together to get a joint list, and then convert to set (and then back to list) to remove duplicates:
df['list_of_codes'] = (df['worker_codes'] df['new_codes']).apply(set).apply(list)
df['Capacity'] = df['list_of_codes'].apply(len)
df[['list_of_codes','Capacity']]
output:
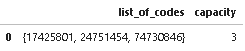
list_of_codes Capacity
0 [17425801, 24751454, 74730846] 3
CodePudding user response:
Use:
df = pd.DataFrame({'worker_codes': [[24751454, 24751454]], 'Capacity': [2], 'new_codes': [[17425801, 74730846]]})
output = {'list_of_codes':[], 'capacity': []}
for i, row in df.iterrows():
temp = row['worker_codes']
temp.extend(row['new_codes'])
temp = set(temp)
output['list_of_codes'].append(temp)
output['capacity'].append(len(temp))
new_df = pd.DataFrame(output)
Actually, you need to merge the values of different columns then add them to a dictionary which then will be used to make a new df. The output: