I am trying to specify the x-axis interval when plotting DataFrames. I have several data files like,
0:0:0 29
0:5:0 85
0:10:0 141
0:15:0 198
0:20:0 251
0:25:0 308
0:30:0 363
0:35:0 413
Where first column is time in %H:%M:%S format but hours goes beyond 24 hours (till 48 hours).
When I read the file as below and plot it looks fine but I want to set the xticks interval to 8 hours.
df0 = pd.read_csv(fil, names=['Time', 'Count'], delim_whitespace=True, parse_dates=['Time'])
df0 = df0.set_index('Time')
ax = matplotlib.pyplot.gca()
mkfunc = lambda x, pos: '%1.1fM' % (x * 1e-6) if x >= 1e6 else '%1.1fK' % (x * 1e-3) if x >= 1e3 else '%1.1f' % x
mkformatter = matplotlib.ticker.FuncFormatter(mkfunc)
ax.yaxis.set_major_formatter(mkformatter)
ax.xaxis.set_major_locator(mdates.HourLocator(interval=8))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H'))
df0.plot(ax=ax, x_compat=True, color='blue')
plt.grid()
plt.savefig('figure2.pdf',dpi=300, bbox_inches = "tight")
I tried the above method as specified by many answers here but that resulted in the following warning,
Locator attempting to generate 1874 ticks ([-28.208333333333332, ..., 596.125]), which exceeds Locator.MAXTICKS (1000).
The figure also displayed many vertical lines. I tried converting my time column specifically to timedelta and it still did not help. I converted to timedelta as below.
custom_date_parser = lambda x: pd.to_timedelta(x.split('.')[0])
df0 = pd.read_csv(fil, names=['Time', 'Count'], delim_whitespace=True, parse_dates=['Time']), date_parser=custom_date_parser)
Could you please help me to identify the issue and set the xticks interval correctly?
CodePudding user response:
The problem here is that a) matplotlib/pandas don't have much support for timedelta objects and b) you cannot use the HourLocator with your data because after conversion to a datetime object, your axis would be labelled 0, 8, 16, 0, 8, 16...
Instead, we can convert the timedelta imported by your converter into hours and plot the numerical values:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
import numpy as np
custom_date_parser = lambda x: pd.to_timedelta(x.split('.')[0])
df0 = pd.read_csv("test.txt", names=['Time', 'Count'], delim_whitespace=True, parse_dates=['Time'], date_parser=custom_date_parser)
#conversion into numerical hour value
df0["Time"] /= np.timedelta64(1, "h")
df0 = df0.set_index('Time')
ax = matplotlib.pyplot.gca()
df0.plot(ax=ax, x_compat=True, color='blue')
mkfunc = lambda x, pos: '%1.1fM' % (x * 1e-6) if x >= 1e6 else '%1.1fK' % (x * 1e-3) if x >= 1e3 else '%1.1f' % x
mkformatter = matplotlib.ticker.FuncFormatter(mkfunc)
ax.yaxis.set_major_formatter(mkformatter)
#set locator at regular hour intervals
ax.xaxis.set_major_locator(MultipleLocator(8))
ax.set_xlabel("Time (in h)")
plt.grid()
plt.show()
Sample output:
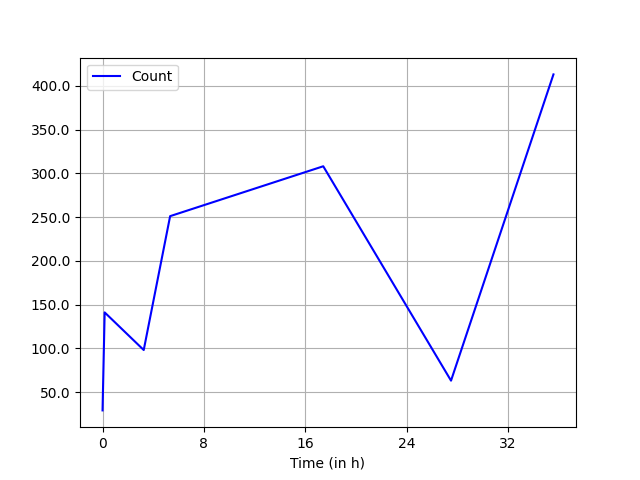
If for reasons unknown you actually need datetime objects, you can convert your timedelta values using an arbitrary offset, as you intend to ignore the day value:
df0["Time"] = pd.to_datetime("2000-01-01 00:00:00 UTC")
But I doubt this will be of advantage in your case.
As an aside - for debugging, it is useful not to use regularly spaced test data. In your example, you probably did not notice that the graph was plotted against the index (0, 1, 2...) and then relabeled with strings, imitating regularly spaced datetime objects. The following test data immediately reveal the problem.
0:0:0 29
0:5:0 85
0:10:0 141
3:15:0 98
5:20:0 251
17:25:0 308
27:30:0 63
35:35:0 413