I wonder how to create new columns in Pandas dataframe with flags if the element in a list existing in another column? updated: The list will be updated frequently and can be very dynamic and long. Is there any way to create flags based on a dynamic list? Thank you.
Thank you so much.
list =['apple', 'banana', 'peach']
Input dataframe:
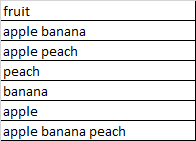
Output dataframe:
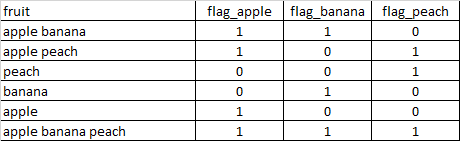
CodePudding user response:
Try to explode fruit column into rows of fruit name then pivot your dataframe:
out = df.join(df['fruit'].str.split().explode().reset_index().assign(count=1)
.pivot_table('count', 'index', 'fruit', fill_value=0)
.add_prefix('flag_'))
Output:
>>> out
fruit flag_apple flag_banana flag_peach
0 apple banana 1 1 0
1 apple peach 1 0 1
2 peach 0 0 1
3 banana 0 1 0
4 apple 1 0 0
5 apple banana peach 1 1 1
CodePudding user response:
Here's a quick implementation of what I think you're trying to do.
import pandas as pd
fruits = ['apple','banana','peach'] # list of fruit
df = pd.DataFrame( # build dataframe
{'fruit':[
'apple banana',
'apple peach',
'peach',
'banana',
'apple',
'apple banana peach']})
for f in fruits:
df[f'flag_{f}'] = df['fruit'].str.count(f)
print(df)
Resulting output:
fruit flag_apple flag_banana flag_peach
0 apple banana 1 1 0
1 apple peach 1 0 1
2 peach 0 0 1
3 banana 0 1 0
4 apple 1 0 0
5 apple banana peach 1 1 1
CodePudding user response:
Here is my attempt:
import pandas as pd
fruits = ['apple','banana','peach']
d = {"fruit" : ["apple banana", "apple peach", "peach","banana", "apple","apple banana peach"]}
df = pd.DataFrame(d)
x=[]
for elem in d['fruit']:
x.append(elem.split(" "))
for f in fruits:
df[f'flag_{f}'] = list(map(lambda e: int(f in e), x))
print(df)
I break the strings up into lists first and then check for membership using a lambda to create the new flag columns.
Output:
fruit flag_apple flag_banana flag_peach
0 apple banana 1 1 0
1 apple peach 1 0 1
2 peach 0 0 1
3 banana 0 1 0
4 apple 1 0 0
5 apple banana peach 1 1 1
CodePudding user response:
Use explode and unstack
(df.assign(f = df['fruit'].str.split())
.explode('f')
.assign(v=1)
.set_index(['fruit','f'])
.unstack(fill_value=0)
.droplevel(level=0,axis=1)
.rename(columns = lambda c : f'flag_{c}')
.reset_index()
)
output
fruit flag_apple flag_banana flag_peach
-- ------------------ ------------ ------------- ------------
0 apple 1 0 0
1 apple banana 1 1 0
2 apple banana peach 1 1 1
3 apple peach 1 0 1
4 banana 0 1 0
5 peach 0 0 1