Given this list:
['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.', 'Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']
How could i return lists separated by a full stop? returning this:
['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.'][ 'Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']
Thanks for any help
CodePudding user response:
You can use a simple loop:
l = ['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.', 'Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']
out = [[]]
for i, e in enumerate(l):
out[-1].append(e)
if e == '.' and i 1 != len(l):
out.append([])
output:
[['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.'],
['Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.'],
]
CodePudding user response:
I would create a generator:
def sentences_generator(lst):
sentence = []
for w in lst:
sentence.append(w)
if w == '.':
yield sentence
sentence = []
And then I would use it in this way (lst is your list of words):
sentences = list(sentences_generator(lst))
CodePudding user response:
[s.strip().split() ["."] for s in " ".join(l).split(".") if s]
- join with spaces
- split on periods
- include only those items that are not empty
- include items that are a joined list of
- stripped sentences
- resplit by spaces
- appended by a last item period
output:
[['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.'], ['Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']]
CodePudding user response:
Use the join-split method, as detailed in 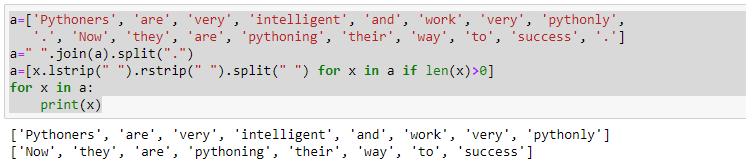
CodePudding user response:
You could do it using itertools.groupby. The group numbers would be formed by alternating True/False based on items being the stop value or not.
from itertools import groupby
R = [list(g) ['.'] for d,g in groupby(L,lambda n:n!='.') if d]
print(R)
[['Pythoners', 'are', 'very', 'intelligent', 'and', 'work',
'very', 'pythonly', '.'],
['Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']]
Note that there will always be a '.' at the end of each group in the output even if the last item doesn't end with a '.'. Also, this will not output empty groups between two '.' items.
For a more generalized solution that includes empty groups and doesn't add any extra '.', you can use accumulate to obtain a new group number after each '.' item encountered:
from itertools import chain, accumulate, groupby
group = chain([0],accumulate(c=='.' for c in L))
R = [list(g) for _,g in groupby(L,lambda _:next(group))]
CodePudding user response:
Oneliner using more_itertools.split_after:
result = list(split_after(lst, '.'.__eq__))
Full demo:
from more_itertools import split_after
lst = ['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.', 'Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']
result = list(split_after(lst, '.'.__eq__))
print(result)
Output:
[['Pythoners', 'are', 'very', 'intelligent', 'and', 'work', 'very', 'pythonly', '.'], ['Now', 'they', 'are', 'pythoning', 'their', 'way', 'to', 'success', '.']]