so I've been trying to teach myself R and have a calculator I created in excel that I'm trying to get working in R.
In R, I'd like to calculate a 45 day moving average based on loan prices I have. The data sample in excel is here:
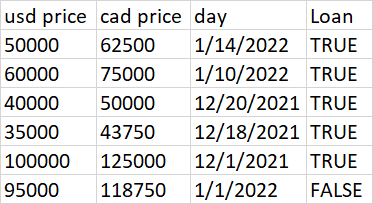
dput output in R is here:
> dput(data)
structure(list(`usd price` = c(50000, 60000, 40000, 35000, 1e 05,
95000), `cad price` = c(62500, 75000, 50000, 43750, 125000, 118750
), day = structure(c(1642118400, 1641772800, 1639958400, 1639785600,
1638316800, 1640995200), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
Loan = c(TRUE, TRUE, TRUE, TRUE, TRUE, FALSE)), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -6L))
In excel, I can do the following formulas (in yellow) to get the correct 45 day moving average result (in blue):

The written out logic is:
- Filter out "Loan" = FALSE values
- Filter out the outliers defined as the top 25% of the previous 45 day values of "usd price" (including the day of)
- Calculate the 45 day average of USD price for the remaining values
Hopefully this makes sense so far. I am having trouble filtering out the top 25% of values in the 45 day set for each row. Here's my R code so far:
data <- data %>% mutate(day=lubridate::parse_date_time(day, "ymd"))
data = data %>%
filter(Loan=="TRUE")%>%
mutate(fourtyfive_avg= rollmean('usd_price',45,
align="right",
fill=0)) %>%
relocate(fourtyfive_avg)
This gives me MA's for each record which I want, but I need to filter out the top quartile before making the MA calculation.
CodePudding user response:
Here’s one way to do it I suppose. Not super efficient because it’s not vectorized, but if your dataset isn’t huge it should work. I made some assumptions on what the result should be because your example calculations and description don’t match. The quartiles in your Excel calculations are across all dates and not just the previous 45 days. I’ve done the calculation so outliers are considered only for the previous 45 days (as you’ve described you want), not across all the data.
If Loan is FALSE I’ve just returned NA, but you could calculate the 45 day average for that date as well using the values in that window that have Loan == TRUE. If it’s the first value in a 45 day window, the result will be that value.
library(tidyverse)
library(lubridate)
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, union
data <-
structure(list(`usd price` = c(50000, 60000, 40000, 35000, 1e 05,
95000), `cad price` = c(62500, 75000, 50000, 43750, 125000, 118750
), day = structure(c(1642118400, 1641772800, 1639958400, 1639785600,
1638316800, 1640995200), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
Loan = c(TRUE, TRUE, TRUE, TRUE, TRUE, FALSE)), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -6L))
data <- data %>% mutate(day=lubridate::parse_date_time(day, "ymd"))
myfunc <- function(x){
fourtyfive_days <- as.Date(x - ddays(45))
if(!data$Loan[data$day %in% x]) return(NA)
data <-
data %>%
filter(day <= x) %>%
filter(day >= fourtyfive_days) %>%
filter(Loan) %>%
filter(`usd price` <= quantile(`usd price`, probs = 0.75)) %>%
summarize(fourtyfive_avg = mean(`usd price`))
return(data$fourtyfive_avg)
}
data$fourtyfive_avg <- sapply(data$day, simplify = TRUE, FUN = myfunc)
To match your calculation and not the description:
myfunc <- function(x){
fourtyfive_days <- as.Date(x - ddays(45))
if(!data$Loan[data$day %in% x]) return(NA)
data <-
data %>%
filter(Loan) %>%
filter(`usd price` <= quantile(`usd price`, probs = 0.75)) %>%
filter(day <= x) %>%
filter(day >= fourtyfive_days) %>%
summarize(fourtyfive_avg = mean(`usd price`))
return(data$fourtyfive_avg)
}
data$fourtyfive_avg <- sapply(data$day, simplify = TRUE, FUN = myfunc)
data %>% arrange(day)
#> # A tibble: 6 x 5
#> `usd price` `cad price` day Loan fourtyfive_avg
#> <dbl> <dbl> <dttm> <lgl> <dbl>
#> 1 100000 125000 2021-12-01 00:00:00 TRUE NaN
#> 2 35000 43750 2021-12-18 00:00:00 TRUE 35000
#> 3 40000 50000 2021-12-20 00:00:00 TRUE 37500
#> 4 95000 118750 2022-01-01 00:00:00 FALSE NA
#> 5 60000 75000 2022-01-10 00:00:00 TRUE 45000
#> 6 50000 62500 2022-01-14 00:00:00 TRUE 46250
CodePudding user response:
Something like this? I have defined a variable ndays to test with the posted data.
Also note that since Loan is a logical variable, there is no need to test the equality with TRUE or "TRUE".
library(dplyr)
library(zoo)
ndays <- 2
data %>%
filter(Loan) %>%
arrange(day) %>%
mutate(q45days = rollapplyr(`usd price`, ndays, quantile, prob = 0.75, fill = NA)) %>%
filter(`usd price` < q45days) %>%
select(-q45days) %>%
mutate(fourtyfive_avg= rollmeanr(`usd price`, 45, fill = 0)) %>%
relocate(fourtyfive_avg)