from scrapy import Spider
from scrapy.http import Request
class AuthorSpider(Spider):
name = 'book'
start_urls = ['https://www.amazon.sg/s?k=Measuring Tools & Scales&i=home&crid=1011S67HHJSEW&sprefix=measuring tools & scales,home,408&ref=nb_sb_noss']
def parse(self, response):
books = response.xpath("//h2/a/@href").extract()
for book in books:
url = response.urljoin(book)
yield Request(url, callback=self.parse_book)
def parse_book(self, response):
rows = response.xpath('//table[@id="productDetails_techSpec_section_1"]//tr')
table = {}
for row in rows:
key = row.xpath('.//th//text()').get(default='').strip()
value = row.xpath('.//td/text() | .//td//span/text()').get().replace("\u200e", "")
value = ''.join(value).strip()
table.update({key: value})
yield table
I want to scrape only brand and ASIN from the table I scape the text from the product information these is the link 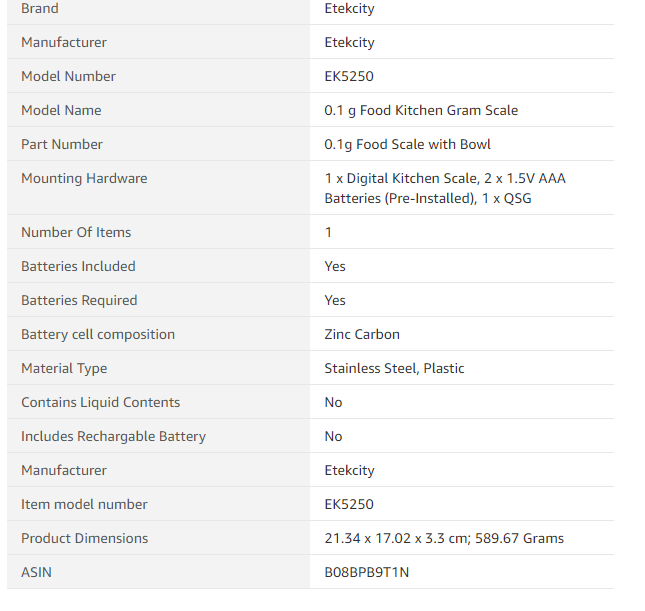
CodePudding user response:
If you just need brand and ASIN you don't need to iterate through the whole table. You can use xpath to directly select those attributes. One way to do it is using following.
brand = response.xpath("//th[@class='a-color-secondary a-size-base prodDetSectionEntry' and contains(text(), 'Brand')]/following-sibling::td/text()").get()
asin = response.xpath("//th[@class='a-color-secondary a-size-base prodDetSectionEntry' and contains(text(), 'ASIN')]/following-sibling::td/text()").get()
You might need to clean up the resulting text a bit. All this xpath is saying is "find the th tag with the right class and with a text of 'Brand' or 'ASIN' then look ahead to the next TD tag and grab that text."