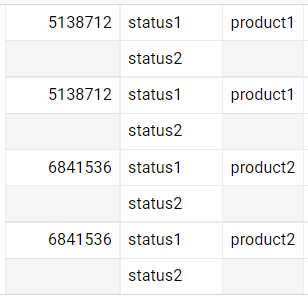
there is a table in BigQuery that has REPEATED type columns and has duplicated rows, since the table has arrays I cannot use distinct to grab only one row.
Table looks something like this:
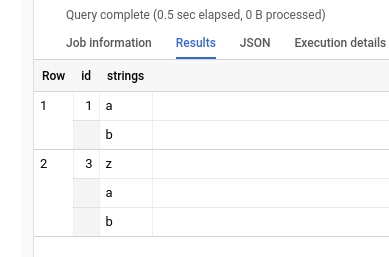
I want to remove the duplicated rows, the output should be like this:
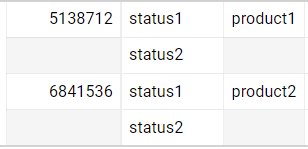
I didn't find a way to come up with the above result, anyone can help?
CodePudding user response:
add 1 columnXYZ with autogenerated number or create numbering in this column by yourself. 1 unique number per each row.
then make query with grouping to your data and "select max(columnXYZ) as RowsToDelete" for each group, this will select only last duplicates in your data. then make deletion by these RowsToDelete.
CodePudding user response:
Consider below approach
select *
from your_table t
where true
qualify 1 = row_number() over(partition by format('%t', t))
CodePudding user response:
I use sample data. This case the id number 1 was duplicated. You can use this query.
WITH data AS (
SELECT 1 id, ["a", "a", "b"] strings
UNION ALL
SELECT 1 id, ["a", "a", "b"] strings
UNION ALL
SELECT 3 id, ["z", "a", "b"] strings
)
SELECT id, ARRAY_AGG(DISTINCT string) strings
FROM data, UNNEST(strings) string
GROUP BY id
This was my result.