I have an excel file that looks like:
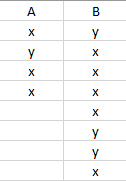
I would like to read this into pandas dataframe and avoid getting NAN values. The reason I am trying to avoid getting NAN is that later on, I want to create a simple contingency table similar to this
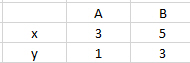
and NAN values create issues in this contingency table. Is there any elegant way of doing this without reading columns separately, using value_counts(), and concatenating the series, as below?
df_1=pd.read_excel('Book1.xlsx', usecols='A')
df_2=pd.read_excel('Book2.xlsx', usecols='B')
value_c_1 = df_1.value_counts()
value_c_2 = df_2.value_counts()
pd.concat([value_c_1, value_c_2], axis=1)
There must be an elegant way of doing this; my apologies if the answer is so obvious; I searched for it before posting this question.
CodePudding user response:
If your excel is like following dataframe :
df = pd.DataFrame({'A' : ['x','y','x','x', '','','',''],
'B' : ['y', 'x','x','x','x','y','y','x',]})
You can try this :
df.apply(pd.value_counts).loc[['x','y']]