I want to create market profile from 30 minute data. And rather than letters i want the sum of letters at a price (example: a price 2500.00 = 'abcdefg' will instead be 2500.00 = 7)
market profile is the concept of showing price on the vertical axis and time on the horizontal axis and each letter denotes 30 minutes of trading activity
for example :
9:30 to 9:59 = 'a'
10:00 to 10:29 = 'b'
10:30 to 10:59 = 'c'
and so on till the end of trading day, with every 30minute being given a new letter
and let say at 9:30 to 9:59 the High is 2505 and Low is 2502 then it will show as
2505 = a
2504 = a
2503 = a
2502 = a
2501 =
2500 =
and let say at 10:00 to 10:29 the High is 2503 and Low is 2500 then it will show as
2505 = a
2504 = a
2503 = ab
2502 = ab
2501 = b
2500 = b
and let say at 10:30 to 10:59 the High is 2502 and Low is 2500 then it will show as
2505 = a
2504 = a
2503 = ab
2502 = abc
2501 = bc
2500 = bc
Now what i want is the sum of letter at each price for each day. To do so i have created a list containing data.table that contains 30m bar data for one day so that is around 40 rows per data.table. And i have created a corresponding list which contains the Low price to High price sequence by .25 for corresponding day.
And what the code is doing is seeing if the Low and High for each 30m bar data(in 'es.d') is lower and higher than each price from Low to High(in 'es.mp') and if so it means within that 30m the price did trade there and hence 1 to the tpo column next to price in 'es.mp'
so the example in letters above would look like
2505 = 1
2504 = 1
2503 = 2
2502 = 3
2501 = 2
2500 = 2
'es.d' is the list containing 30m data for a day
str(es.d)
List of 1291
$ 2016/7/18 :Classes ‘data.table’ and 'data.frame': 47 obs. of 12 variables:
..$ Date : chr [1:47] "2016-07-18 00:00:00" "2016-07-18 00:30:00" "2016-07-18 01:00:00" "2016-07-18 01:30:00" ...
..$ Open : num [1:47] 2156 2156 2156 2158 2156 ...
..$ High : num [1:47] 2157 2157 2158 2158 2158 ...
..$ Low : num [1:47] 2156 2156 2156 2156 2156 ...
..$ Last : num [1:47] 2156 2156 2158 2156 2158 ...
..$ Volume : num [1:47] 1827 1921 2856 3096 2883 ...
..$ # of Trades: num [1:47] 1017 834 1525 1759 1593 ...
..$ OHLC Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ HLC Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ HL Avg : num [1:47] 2156 2156 2157 2157 2157 ...
..$ Bid Volume : num [1:47] 1000 826 1083 1709 1508 ...
..$ Ask Volume : num [1:47] 827 1095 1773 1387 1375 ...
..- attr(*, ".internal.selfref")<externalptr>
'es.mp' is the corresponding list containing Low to High price for that day in .25 increment
str(es.mp)
List of 1291
$ 2016/7/18 :Classes ‘data.table’ and 'data.frame': 43 obs. of 2 variables:
..$ price: num [1:43] 2153 2153 2153 2154 2154 ...
..$ tpo : num [1:43] 0 0 0 0 0 0 0 0 0 0 ...
..- attr(*, ".internal.selfref")=<externalptr>
And just to add for both the list, data.table in each element don't necessarily have the same amount of rows
Here is the code and it has 3 for loops and its taking way too long or forever if you will
for(i in 1:length(es.d)){
for(j in 1:nrow(es.d[[i]])){
for(k in 1:nrow(es.mp[[i]])){
es.mp[[i]] = es.mp[[i]][k,tpo := nrow(es.d[[i]][Low<=es.mp[[i]][k,price] & High>=es.mp[[i]][k,price]])]}}}
CodePudding user response:
It sounds like you are looking for a frequency table showing how many 30m periods spanned various price points. Here is a quick dplyr/tidyr approach. The crucial thing here is that the way you've set up your loops is highly nested and it doesn't take advantage of R's speed advantage for "vectorized" calculations: 
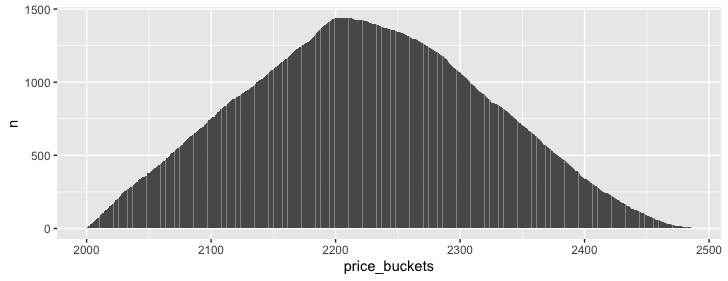
How often was each 0.25 price level breached? Here I make a vector of price levels, then cross that with the fake data, and count the number of times each price bucket was crossed. In this case, 30 days of 30m periods = 1,440 periods, multiplied by about 2000 price buckets = 2.8M rows, which is a very manageable size and can calculate in <1 sec.
price_bucket = seq(from = floor(min(fake_data$Low)/0.25)*0.25,
to = ceiling(max(fake_data$High)/0.25)*0.25,
by = 0.25)
crossing(fake_data, price_buckets) %>%
filter(Low <= price_buckets, High >= price_buckets) %>%
count(price_buckets) %>%
ggplot(aes(price_buckets, n))
geom_col()
It gets slower for more days, in my case about 10 sec for 1000 days. I presume converting to data.table syntax would be faster, but I'm not knowledgeable enough yet in how to do so best.
CodePudding user response:
Taking from what Jon Spring advised, here is how i avoided the for loop altogether. I still think it can be faster, but for now this works just fine.
Here is the code
library(data.table); library(dplyr); library(tidyr)
mp = function(x,y){
tpo = data.table(crossing(x, y) %>%
filter(Low <= y, High >= y) %>%
count(y))
setnames(tpo,c('y','n'),c('price','tpo'))}
es.mp = lapply(es.d,function(x) mp(x[,.(Low,High)],seq(min(x[,Low],na.rm=T),max(x[,High],na.rm=T),.25)))