I have some data in the format of (x, y, class) like the following:
data = [(1, 2, 'A'), (2, 3, 'A'), (3, 4, 'A'), (4, 5, 'A'), (5, 6, 'A'), (1, 4, 'B'), (2, 5, 'B'), (3, 6, 'B'), (4, 7, 'B'), (5, 8, 'B'), (1, 3, 'C'), (2, 4, 'C'), (3.1, 5, 'C'), (4.1, 6, 'C'), (5.1, 7, 'C')]
And I would like to plot it using pandas. If one uses the commands:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data, columns = ['x', 'y', 'c'])
df.pivot(index = 'x', columns = 'c', values = 'y').plot()
plt.show()
The output is as follows
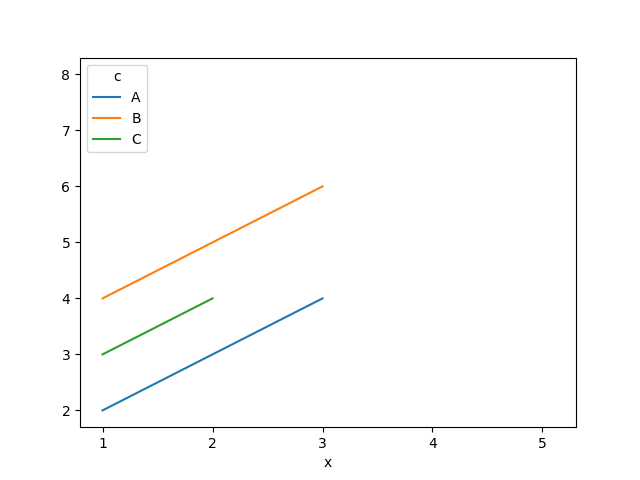
If instead we drop class C using:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(data, columns = ['x', 'y', 'c'])
df[df['c'].isin(['A', 'B'])].pivot(index = 'x', columns = 'c', values = 'y').plot()
plt.show()
The output is
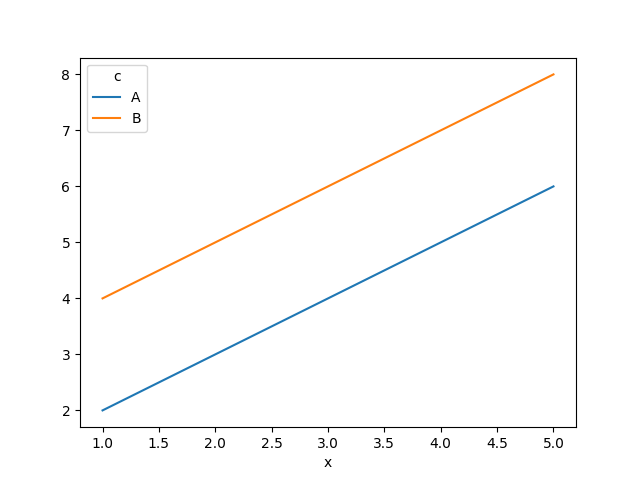
This is straightforward: because class C has some different x values, we end up with some nan results in the values columns which means pandas cannot plot the data.
I could use interpolate to fill in the missing values, as my data is not incredibly large, but the scale of my data is sufficiently large that it would make more sense to just plot class 'C' on top of the plot with the other two, meaning it needs to
- Be added to the legend
- Appear in its entirety on the plot
How can I do this?
CodePudding user response:
Using seaborn is straightforward with lineplot.
import seaborn as sns
sns.lineplot(data=df, x='x', y='y', hue='c')
The other option with pandas is with groupby.
fig, ax = plt.subplots(figsize=(8,6))
for _label, _dfg in df.groupby('c'):
_dfg.plot(x='x',y='y', ax=ax, label=_label)