I want a script to put column values in groups with a maximum range of 10. So that all values in the group are <10 different from each other. I'm trying to get a script that defines the groups, counts how many values are in each group, and find the mean.
So if I had this df:
cat1 = c(85, 60, 60, 55, 55, 15, 0, 35, 35 )
cat2 = c("a","a","a","a","a","a","a","a","a")
df <- data.frame(cat1, cat2)
cat1 cat2
1 85 a
2 60 a
3 60 a
4 55 a
5 55 a
6 15 a
7 0 a
8 35 a
9 35 a
the output would be:
numValues cat1avg
1 85
4 57.5
1 15
1 0
2 35
I followed the top-rated answer 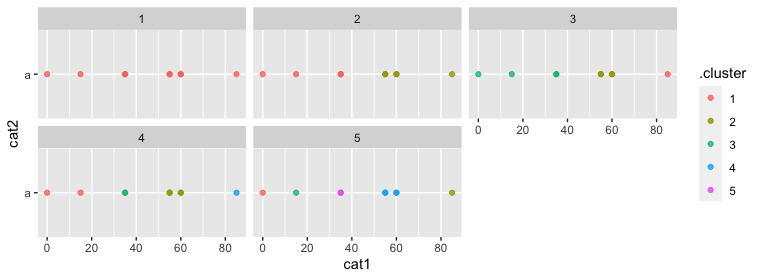
We could see how much range is in each cluster produced in each case, and find the widest range cluster for each k. We see that dividing into four groups would have at least 15 range (see the 4 facet in the chart above), but 5 groups would be adequate to keep the within-cluster range under 5.
assignments %>%
group_by(k, .cluster) %>%
summarize(range = max(cat1) - min(cat1)) %>%
summarize(max_range = max(range))
# A tibble: 6 × 2
k max_range
<int> <dbl>
1 1 85
2 2 35
3 3 30
4 4 15
5 5 5
6 6 0
And finally:
assignments %>%
filter(k == 5) %>%
group_by(.cluster) %>%
summarize(numValues = n(),
cat1avg = mean(cat1))
.cluster numValues cat1avg
<fct> <int> <dbl>
1 1 1 85
2 2 1 15
3 3 2 35
4 4 4 57.5
5 5 1 0