I have a dataframe 'raw' that looks like this -
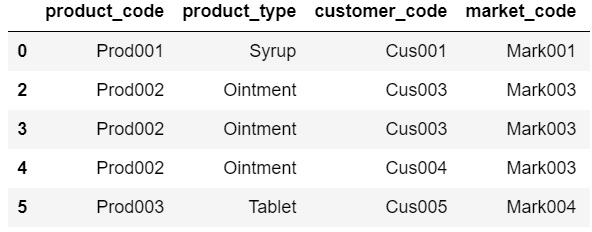
It has many rows with duplicate values in each column.
I want to make a new dataframe 'new_df' which has unique customer_code corresponding and market_code.
The new_df should look like this -
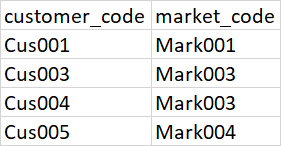
CodePudding user response:
It sounds like you simply want to create a DataFrame with unique customer_code which also shows market_code. Here's a way to do it:
df = df[['customer_code','market_code']].drop_duplicates('customer_code')
Output:
customer_code market_code
0 Cus001 Mark001
1 Cus003 Mark003
3 Cus004 Mark003
4 Cus005 Mark004
The part reading df[['customer_code','market_code']] gives us a DataFrame containing only the two columns of interest, and the drop_duplicates('customer_code') part eliminates all but the first occurrence of duplicate values in the customer_code column (though you could instead keep the last occurrence of each duplicate by calling it using the keep='last' argument).