I have a pandas dataframe
import pandas as pd
df =pd.DataFrame({'name':['john','joe','bill','richard','sam'],
'cluster':['1','2','3','1','2']})
df['cluster'].value_counts() will give the number of occurance of items based on column cluster.
Is it possible to retain the only rows which have maximum number of occurance in the column cluster
The expected output is
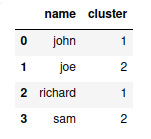
The cluster 1 and 2 have same number of occurances, so all the rows for cluster 1 and 2 needs to be retained
CodePudding user response:
Group by 'cluster' and use transform('count') to get a Series of occurrences by clusters with the appropriate shape. Then use it to mask only the rows corresponding to the max occurrences.
cluster_counts = df.groupby('cluster')['name'].transform('count')
res = df[cluster_counts == cluster_counts.max()]
Output:
>>> res
name cluster
0 john 1
1 joe 2
3 richard 1
4 sam 2
Setup:
import pandas as pd
df = pd.DataFrame({'name':['john','joe','bill','richard','sam'],
'cluster':['1','2','3','1','2']})
CodePudding user response:
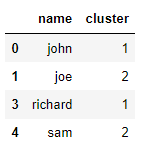
Use this
# find the most common clusters then filter those clusters
df[df.cluster.isin(df.cluster.mode())]
CodePudding user response:
You can get the max count of cluster value through df['cluster'].value_counts() then use isin to filter cluster column
c = df['cluster'].value_counts()
out = df[df['cluster'].isin(c[c.eq(c.max())].index)]
print(out)
name cluster
0 john 1
1 joe 2
3 richard 1
4 sam 2