I have a pandas data frame like this:
Month ID
Sep 21 ID_1
Sep 21 ID_2
Sep 21 ID_3
Oct 21 ID_1
Oct 21 ID_2
Oct 21 ID_4
Oct 21 ID_5
Nov 21 ID_1
Nov 21 ID_2
Nov 21 ID_3
Nov 21 ID_4
Dec 21 ID_2
Dec 21 ID_3
Dec 21 ID_4
Dec 21 ID_5
Jan 22 ID_3
Jan 22 ID_4
Jan 22 ID_5
and i want ID counts in a format like this as the output pandas dataframe:
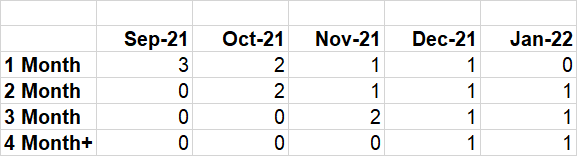
where as values i can get unique count of IDs for each month like ID1 in October 2 should be counted under 2 months as it is appearing for 2 months now and in Nov ID2 will be counted under 3 month as it is consistently appearing for 3 months. But as ID5 appears first time in Oct it will be counted under 1 month in Oct and so on. Any ID which appears more than 4 times should be counted under 4 month category.
In pandas i am not sure how to go about this approach to get this unique count and have a pivot table.
CodePudding user response:
First, this will create a matrix of occurence. Note that I used date-time format for Month for easy-sorting.
step1 = pd.crosstab(
df['ID'],
pd.to_datetime(df['Month'], format='%b %y')
)
Month 2021-09-01 2021-10-01 2021-11-01 2021-12-01 2022-01-01
ID
ID_1 1 1 1 0 0
ID_2 1 1 1 1 0
ID_3 1 0 1 1 1
ID_4 0 1 1 1 1
ID_5 0 1 0 1 1
Then, do the cumulative sum that satisfy the continuity condition
for month_prev, month_next in zip(step1.columns, step1.columns[1:]):
step1[month_next] = (step1[month_next] step1[month_prev]) * step1[month_next]
Month 2021-09-01 2021-10-01 2021-11-01 2021-12-01 2022-01-01
ID
ID_1 1 2 3 0 0
ID_2 1 2 3 4 0
ID_3 1 0 1 2 3
ID_4 0 1 2 3 4
ID_5 0 1 0 1 2
Then, we apply melt, groupby, value_counts to count those cumsum-values for each month, unstack to move Month to the columns, and the rest 3 methods to take care of formatting.
step2 = pd.melt(step1)\
.groupby('Month')['value']\
.value_counts()\
.unstack(level=0)\
.fillna(0)\
.drop(0)\
.astype(int)
Month 2021-09-01 2021-10-01 2021-11-01 2021-12-01 2022-01-01
value
1 3 2 1 1 0
2 0 2 1 1 1
3 0 0 2 1 1
4 0 0 0 1 1
Last step for further formattings:
step2.columns = step2.columns.strftime('%b %y')
step2.loc[4] = step2.loc[step2.index>=4].sum()
step2.index = (step2.index.astype(str) ' Month').str.replace('4 Month', '4 Month ')
Month Sep 21 Oct 21 Nov 21 Dec 21 Jan 22
value
1 Month 3 2 1 1 0
2 Month 0 2 1 1 1
3 Month 0 0 2 1 1
4 Month 0 0 0 1 1