I am trying to scrape the glassdoor with selenium. Currently, my Jupiter notebook opens the new tab and opens the URL I wrote in my code. However, when it tries to start scraping and wants to take the first element, it brings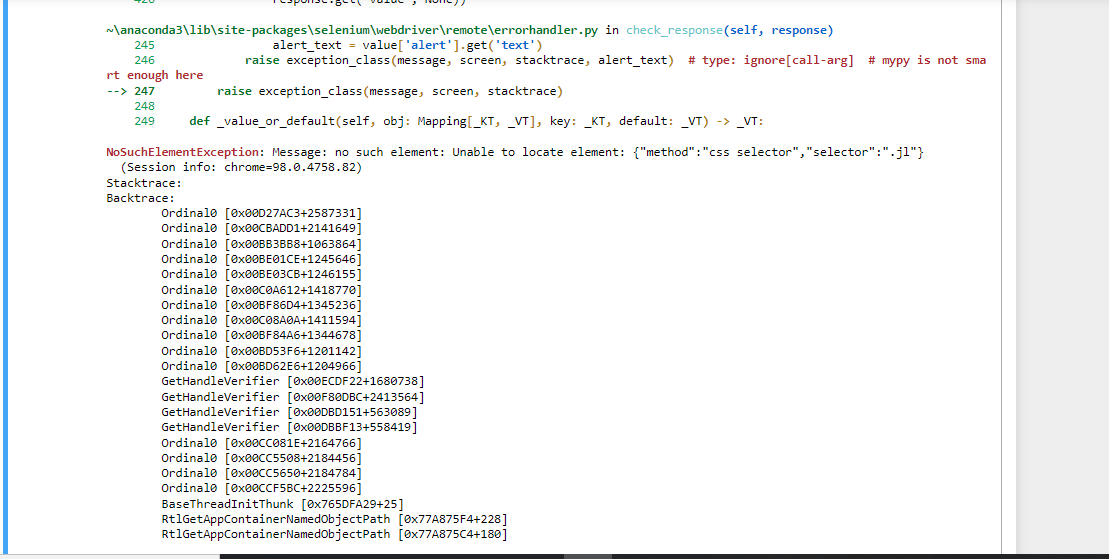 an error. In the picture, you can see the error.
an error. In the picture, you can see the error.
from selenium.common.exceptions import NoSuchElementException, ElementClickInterceptedException
from selenium import webdriver
import time
import pandas as pd
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
def get_jobs(keyword, num_jobs, verbose, slp_time):
'''Gathers jobs as a dataframe, scraped from Glassdoor'''
#Initializing the webdriver
options = webdriver.ChromeOptions()
ser = Service("C:/Users/user/Dropbox/My PC (WIN-QTQTESCD562)/Desktop/ds_salary_proj/chromedriver")
#s = webdriver.Chrome(service=ser, options=op)
#Uncomment the line below if you'd like to scrape without a new Chrome window every time.
#options.add_argument('headless')
#Change the path to where chromedriver is in your home folder.
driver = webdriver.Chrome(service=ser, options=options)
driver.set_window_size(1120, 1000)
url = "https://www.glassdoor.com/Job/jobs.htm?suggestCount=0&suggestChosen=false&clickSource=searchBtn&typedKeyword=" keyword "&sc.keyword=" keyword "&locT=&locId=&jobType="
driver.get(url)
jobs = []
while len(jobs) < num_jobs: #If true, should be still looking for new jobs.
#Let the page load. Change this number based on your internet speed.
#Or, wait until the webpage is loaded, instead of hardcoding it.
time.sleep(4)
#Test for the "Sign Up" prompt and get rid of it.
try:
driver.find_element(By.CLASS_NAME, "selected").click()
except ElementClickInterceptedException:
pass
time.sleep(slp_time)
try:
driver.find_element(By.CLASS_NAME, "ModalStyle__xBtn___29PT9").click() #clicking to the X.
except NoSuchElementException:
pass
#Going through each job in this page
job_buttons = driver.find_element(By.CLASS_NAME, "jl") #jl for Job Listing. These are the buttons we're going to click.
for job_button in job_buttons:
print("Progress: {}".format("" str(len(jobs)) "/" str(num_jobs)))
if len(jobs) >= num_jobs:
break
job_button.click() #You might
time.sleep(1)
collected_successfully = False
while not collected_successfully:
try:
company_name = driver.find_element(By.XPATH, './/div[@]').text
location = driver.find_element(By.XPATH, './/div[@]').text
job_title = driver.find_element(By.XPATH, './/div[contains(@class, "title")]').text
job_description = driver.find_element(By.XPATH, './/div[@]').text
collected_successfully = True
except:
time.sleep(5)
try:
salary_estimate = driver.find_element(By.XPATH, './/span[@]').text
except NoSuchElementException:
salary_estimate = -1 #You need to set a "not found value. It's important."
try:
rating = driver.find_element(By.XPATH, './/span[@]').text
except NoSuchElementException:
rating = -1 #You need to set a "not found value. It's important."
#Printing for debugging
if verbose:
print("Job Title: {}".format(job_title))
print("Salary Estimate: {}".format(salary_estimate))
print("Job Description: {}".format(job_description[:500]))
print("Rating: {}".format(rating))
print("Company Name: {}".format(company_name))
print("Location: {}".format(location))
#Going to the Company tab...
#clicking on this:
#<div data-tab-type="overview"><span>Company</span></div>
try:
driver.find_element(By.XPATH, './/div[@ and @data-tab-type="overview"]').click()
try:
#<div >
# <label>Headquarters</label>
# <span >San Francisco, CA</span>
#</div>
headquarters = driver.find_element(By.XPATH, './/div[@]//label[text()="Headquarters"]//following-sibling::*').text
except NoSuchElementException:
headquarters = -1
try:
size = driver.find_element(By.XPATH, './/div[@]//label[text()="Size"]//following-sibling::*').text
except NoSuchElementException:
size = -1
try:
founded = driver.find_element(By.XPATH,'.//div[@]//label[text()="Founded"]//following-sibling::*').text
except NoSuchElementException:
founded = -1
try:
type_of_ownership = driver.find_element(By.XPATH,'.//div[@]//label[text()="Type"]//following-sibling::*').text
except NoSuchElementException:
type_of_ownership = -1
try:
industry = driver.find_element(By.XPATH,'.//div[@]//label[text()="Industry"]//following-sibling::*').text
except NoSuchElementException:
industry = -1
try:
sector = driver.find_element(By.XPATH,'.//div[@]//label[text()="Sector"]//following-sibling::*').text
except NoSuchElementException:
sector = -1
try:
revenue = driver.find_element(By.XPATH,'.//div[@]//label[text()="Revenue"]//following-sibling::*').text
except NoSuchElementException:
revenue = -1
try:
competitors = driver.find_element(By.XPATH,'.//div[@]//label[text()="Competitors"]//following-sibling::*').text
except NoSuchElementException:
competitors = -1
except NoSuchElementException: #Rarely, some job postings do not have the "Company" tab.
headquarters = -1
size = -1
founded = -1
type_of_ownership = -1
industry = -1
sector = -1
revenue = -1
competitors = -1
if verbose:
print("Headquarters: {}".format(headquarters))
print("Size: {}".format(size))
print("Founded: {}".format(founded))
print("Type of Ownership: {}".format(type_of_ownership))
print("Industry: {}".format(industry))
print("Sector: {}".format(sector))
print("Revenue: {}".format(revenue))
print("Competitors: {}".format(competitors))
print("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@")
jobs.append({"Job Title" : job_title,
"Salary Estimate" : salary_estimate,
"Job Description" : job_description,
"Rating" : rating,
"Company Name" : company_name,
"Location" : location,
"Headquarters" : headquarters,
"Size" : size,
"Founded" : founded,
"Type of ownership" : type_of_ownership,
"Industry" : industry,
"Sector" : sector,
"Revenue" : revenue,
"Competitors" : competitors})
#add job to jobs
#Clicking on the "next page" button
try:
driver.find_element(By.XPATH,'.//li[@]//a').click()
except NoSuchElementException:
print("Scraping terminated before reaching target number of jobs. Needed {}, got {}.".format(num_jobs, len(jobs)))
break
return pd.DataFrame(jobs) #This line converts the dictionary object into a pandas DataFrame.
df = get_jobs("data scientist", 5, False, 15)
This was my whole code. How can I fix it?
CodePudding user response: