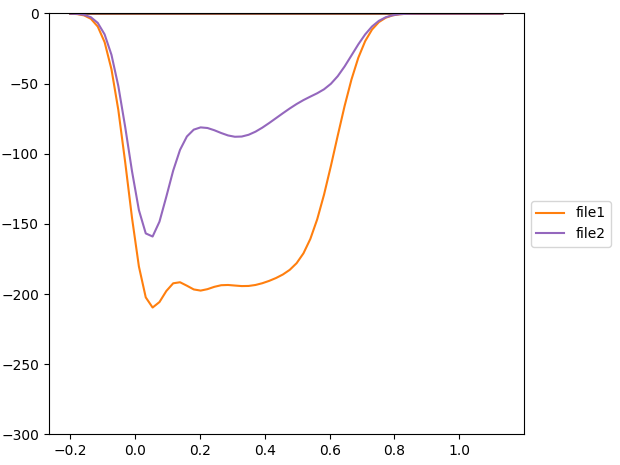
I have multiple .dat files looking like this: 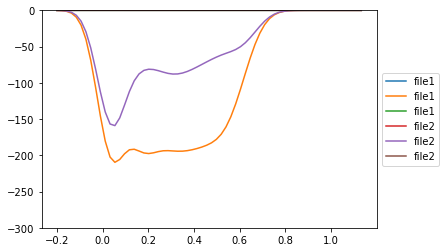
Thus, I edited the code to remove the legend duplicates (the last 3 rows in the code):
z_bins = 541
h_bins = 65
for nr in [1,2]:
array = []
profile = "file_{}.dat".format(nr)
d,h,en,de,dh = npy.loadtxt(profile,comments="#",unpack=True)
s = 0
e = z_bins
selected = npy.linspace(0,z_bins-1,3)
for i in selected:
i = int(i)
plt.plot(h[i:i (h_bins-1)*z_bins:z_bins],en[i:i (h_bins-1)*z_bins:z_bins],label='file{}' .format(nr))
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.ylim(-300,0)
handles, labels = plt.gca().get_legend_handles_labels()
by_label = dict(zip(labels, handles))
plt.legend(by_label.values(), by_label.keys())
The results looks like this:
I'm glad that legend duplicates are gone, however the colors in the legend don't match colors of the lines in the graph.
I assume that it happened because I deleted duplicates from the legend but their colors/lines remained in the plot itself. I'd like to fix it in a way that the colors in legend would match the colors of the lines. I tried to fix it this way: firstly set that duplicates have same color (e.g. all 'file1' would be blue, all "file2' would be red), and then removing the duplicates itself. However, I wasn't succesful with this approach. Could anybody, please, help me with suggestions how to deal with it?
CodePudding user response:
I'm not sure if your approach makes much sense: the remaining four lines are not visible as the are approximately zero (i.e. they are all plotted one over the other at the top spine of the plot).
If you know, however, that there are always only some lines with significant values you can assign labels for these lines only and and underscore for the remaining lines that shouldn't appear in the legend (labels starting with an underscore are not included in the legend):
plt.plot(h[i:i (h_bins-1)*z_bins:z_bins],
en[i:i (h_bins-1)*z_bins:z_bins],
label='file{}'.format(nr) if min(en[i:i (h_bins-1)*z_bins:z_bins]) < -10 else '_')