Suppose we have this data frame:
> data
ID Period_1 Values
1 1 2020-03 -5
2 1 2020-04 25
3 2 2020-01 35
4 2 2020-02 45
5 2 2020-03 55
6 2 2020-04 87
7 3 2020-02 10
8 3 2020-03 20
9 3 2020-04 30
data <-
data.frame(
ID = c(1,1,2,2,2,2,3,3,3),
Period_1 = c("2020-03", "2020-04", "2020-01", "2020-02", "2020-03", "2020-04", "2020-02", "2020-03", "2020-04"),
Values = c(-5, 25, 35, 45, 55, 87, 10, 20, 30)
)
I would like to extract the minimum of "Values", but subject to the condition that a Period_1 condition is met (such as Period_1 == "2020-04"). My inclination is to use dplyr group_by(Period_1) %>% but I don't need the minimum for all Period_1 groupings, I just need the minimum of Values for the single specified period. The actual database I am working with has 2 million rows and I suspect my abundant use of group_by(...) is slowing things down dramatically.
Other Stack Overflow (and Google, etc.) posts I reviewed also rely on group_by, maybe this is the quickest way to process this, I don't know, but I suspect not.
I tried the following but it didn't work: data %>% select(where(data$Period_1 == "2020-04"))%>% min(data$Values, na.rm=TRUE), returning the message "Error: Can't convert a logical vector to function"
Processing speed-wise, which is the fastest way to extract a conditional minimum? Including by use of dplyr.
CodePudding user response:
You are confusing dplyr::filter with dplyr::select.
select(where(condition)) selects columns based on a logical condition that is aplied to the whole vector/column, as in select(where(is.numeric)), which selects numeric columns.
To select rows that meet a condition, use filter.
library(dplyr)
data %>%
filter(Period1 == "2020-04") %>%
pull(Values) %>%
min(na.rm = TRUE)
# OR with `summarise`
data %>%
filter(Period1 == "2020-04") %>%
summarise(min_Values = min(Values, na.rm = TRUE))
CodePudding user response:
Here is a base R option (if you are looking for speed). We can subset the data, then get the minimum value for the third (i.e., Values) column.
min(data[data$Period_1 == "2020-04", ][,3], na.rm = TRUE)
# [1] 25
Benchmark
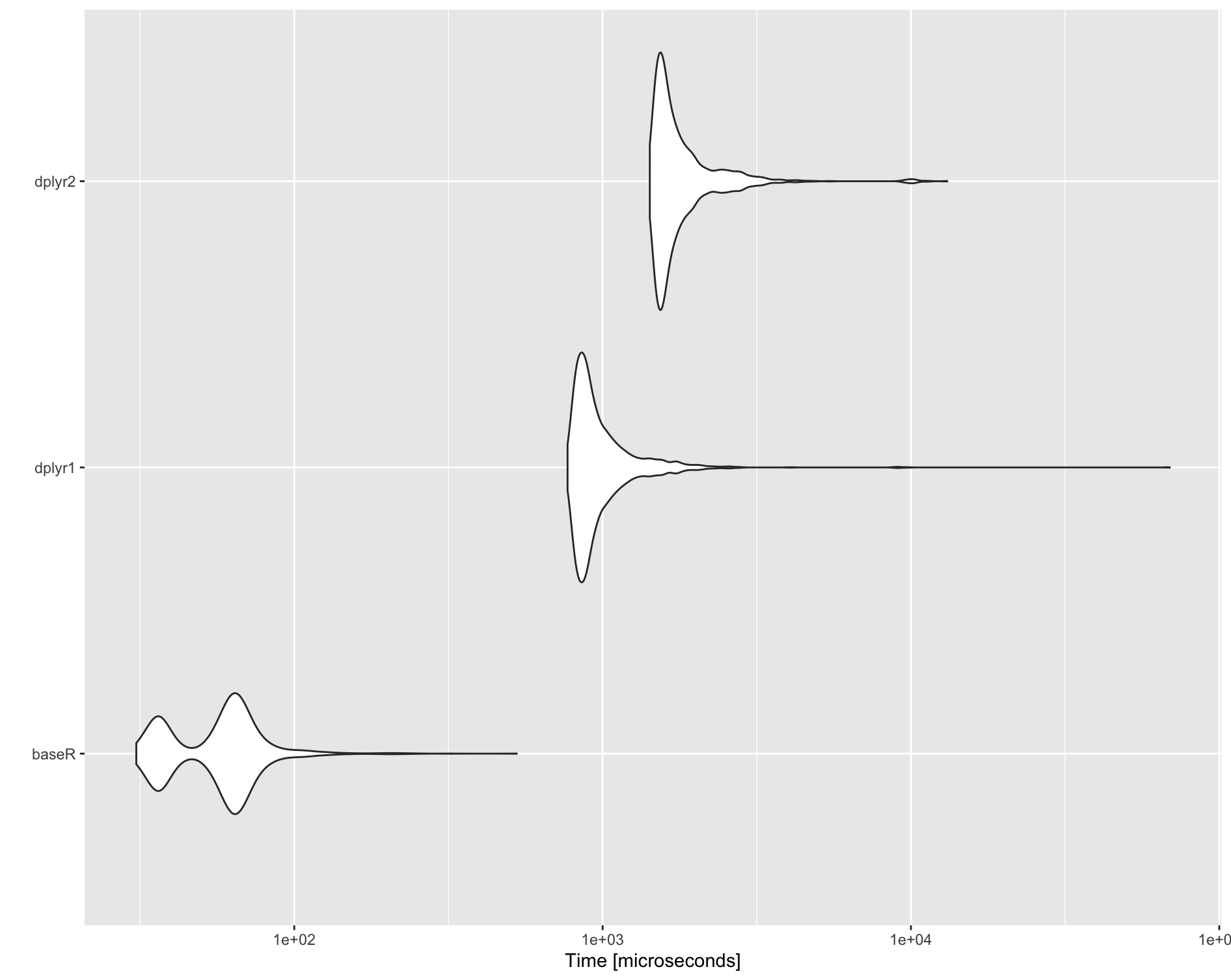
CodePudding user response:
Here is another base R function, that follows the lines of Andrew's answer but is faster for small to medium data sets. Then the 2 base R and GuedesBF dplyr solutions are timed and the timings plotted.
data <-
data.frame(
ID = c(1,1,2,2,2,2,3,3,3),
Period_1 = c("2020-03", "2020-04", "2020-01", "2020-02", "2020-03", "2020-04", "2020-02", "2020-03", "2020-04"),
Values = c(-5, 25, 35, 45, 55, 87, 10, 20, 30)
)
library(dplyr)
library(ggplot2)
library(microbenchmark)
f1 <- function(data, period){
i <- data[["Period_1"]] == period
min(data$Values[i], na.rm = TRUE)
}
f2 <- function(data, period){
min(data[data$Period_1 == period, 3], na.rm = TRUE)
}
f3 <- function(data, period){
data %>%
filter(Period_1 == period) %>%
pull(Values) %>%
min(na.rm = TRUE)
}
funTest <- function(n, X = data, period = "2020-04"){
out <- lapply(seq.int(n), function(k){
y <- X
for(i in seq.int(k)) y <- rbind(y, y)
mb <- microbenchmark(
base_Rui = f1(y, period),
base_Andrew = f2(y, period),
dplyr_GuedesBF = f3(y, period)
)
mb$nrow <- nrow(y)
aggregate(time ~ expr nrow, mb, median)
})
do.call(rbind, out)
}
timings <- funTest(20)
ggplot(timings, aes(nrow, time, color = expr))
geom_line()
geom_point()
scale_x_continuous(trans = "log10")
scale_y_continuous(trans = "log10")
theme_bw()
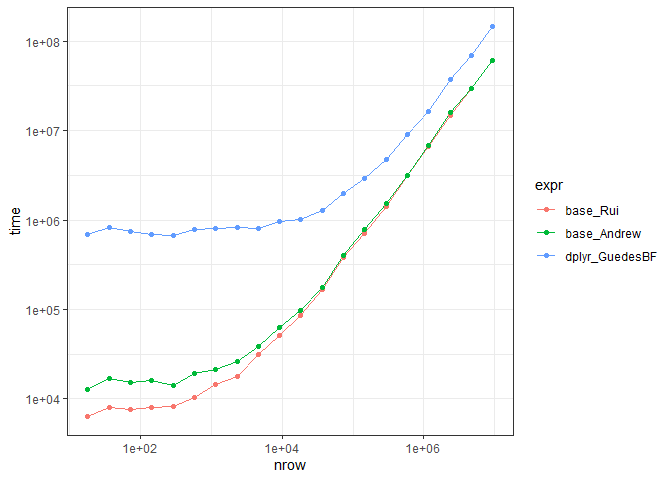
Created on 2022-02-03 by the reprex package (v2.0.1)
CodePudding user response:
Have you considered the grep() function