This is my example of XML
<Data>
<Month>11</Month>
<Year>2021</Year>
<Customer>
<Name>ABC</Name>
</Customer>
<Contracts>
<Contract Direction="OUT" count="60">
<Partner>
<Name>A</Name>
</Partner>
<Documents>
<Document type="ORDER" count="10"/>
<Document type="INVOICE" count="20"/>
<Document type="OFFER" count="30"/>
</Documents>
</Contract>
<Contract Direction="IN" count="47">
<Partner>
<Name>B</Name>
</Partner>
<Documents>
<Document type="ORDER" count="47"/>
</Documents>
</Contract>
<Contract Direction="OUT" count="37">
<Partner>
<Name>ABC</Name>
</Partner>
<Documents>
<Document type="ORDER" count="37"/>
</Documents>
</Contract>
</Contracts>
</Data>
and I'm using this SQL Syntax
SELECT
CAST(cast((xpath('//Year/text()', myTempTable.myXmlColumn))[1]as varchar) as integer) AS YearNo
,CAST(cast((xpath('//Month/text()', myTempTable.myXmlColumn))[1]as varchar) as integer) AS MonthNo
,(xpath('//Customer/Name/text()', myTempTable.myXmlColumn))[1]::text AS CustomerName
,unnest(xpath('//Contracts/Contract/Partner/Name/text()', myTempTable.myXmlColumn))::text AS Partner
,unnest(xpath('//Contracts/Contract/@Direction', myTempTable.myXmlColumn))::text AS DocumentType
,unnest(xpath('//Contracts/Contract/Documents/Document/@type', myTempTable.myXmlColumn))::text AS DocumentType
,unnest(xpath('//Contracts/Contract/Documents/Document/@count', myTempTable.myXmlColumn))::text AS countDoc
FROM unnest(
xpath
( '//Data'
,XMLPARSE(DOCUMENT convert_from(pg_read_binary_file('testXML.xml'), 'UTF8'))
)
) AS myTempTable(myXmlColumn)
order by 5;
Issue is that results by partner and document type are wrong
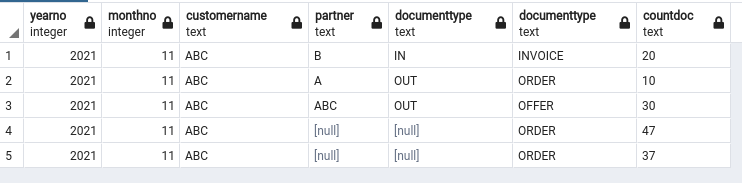
Do you have any ideas ?
Additional do you have any ideas how to run this kind of script for more than 500 xml files ?
CodePudding user response:
Complex XML parsing is easier done using xmltable(). As far as I can tell, the following should return what you want:
select x.*
from the_table
cross join xmltable('/Data/Contracts/Contract/Documents/Document'
passing content
columns
year int path '//Year',
month int path '//Month',
customer_name text path '//Customer/Name',
partner_name text path 'ancestor::Contract/Partner/Name',
document_type text path 'ancestor::Contract/@Direction',
type text path '@type',
countdoc int path '@count'
) as x
Passing '/Data/Contracts/Contract/Documents/Document' as the initial XPath results in one row per Document in the result. The access to the attributes and elements "higher up", is then done using the ancestor selector for those that depend on the Contract.
The elements that are independent of the number of contracts are accessed through an absolute path starting at //