This is the code I have tried and have been getting the following results. Have tried various approaches to this problem. The data into the CSV file seems to be spread over multiple columns and rows which is not ideal for my project. I have come to an understanding that there might be a memory of a single cell threshold that causing this problem.
for i in range(len(read1)):
if read1[i] in opcodes:
seq = seq " " read1[i]
print(seq)
csvname="/content/drive/MyDrive/sequence.csv"
#approach1
'''
dict1 = {"sequence":seq, "target":1}
'''
#apprach 2
'''
with open(csvname, 'w') as csvfile:
csvwriter = csv.writer(csvfile)
# writing the fields
# writing the data rows
csvwriter.writerow(seq)
break
'''
'''
a_file = open(csvname, "w", newline="")
df = pd.DataFrame(dict1, index=[0])
#print(df)
# saving the dataframe
df.to_csv('/content/drive/MyDrive/sequence.csv', mode='a', index=False, header=False)
'''
#approach 3 -- very bad results
'''
csv_file = open(csvname, "w")
csv_file.write(seq)
'''
a_file.close()
Please not that I have commented various approaches to this problem and all the approaches seem to give a similar output
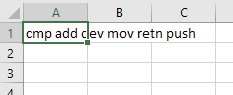
But if you drag the column you would get:
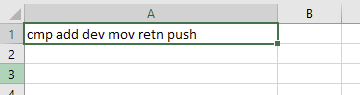
If you want to automatically change how Excel displays the data, you would need to save your data in Excel format .xlsx. The column width could then be specified. This could be done using a library such as openpyxl.
Note: a second column could be added as follows:
csv.writer(f_output).writerow([seq, 'a second column'])