How one can plot the count of the n most frequent elements across all groups for a given multi group time series? Note this is different from n most frequent elements of each group, which I could easily accomplish with count and nlargest.
Let's dive into an example. Given a dataframe:
import pandas as pd
data = {'year': [2020, 2020, 2021, 2021, 2022],
'month': [1, 1, 2, 2, 3],
'Name': ['name_1', 'name_2', 'name_1', 'name_2', 'name_1'],
'count': [10, 12, 8, 10, 2]}
df = pd.DataFrame(data)
print(df)
which outputs
year month Name Count
0 2020 1 name_1 10
1 2020 1 name_2 12
2 2021 2 name_1 8
3 2021 2 name_2 10
4 2022 3 name_1 2
- data should be grouped by
yearandmonth - I want
n = 1, in other words the most frequent one
I would like to plot only name_1's count since, although it does not have the largest count in any group (or even overall), it "appears" more times across all groups.
CodePudding user response:
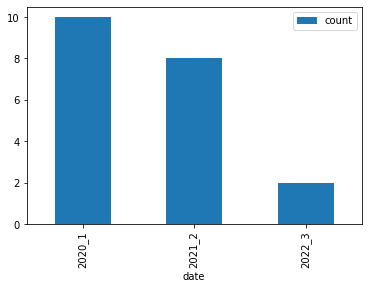
IIUC, you want to filter the most common Name and plot the counts?
# get top Name
top = df['Name'].value_counts().index[0]
# filter
df2 = df[df['Name'].eq(top)]
# plot
(df2.assign(date=df2[['year', 'month']].astype(str).apply('_'.join, axis=1))
.plot.bar(x='date', y='count')
)
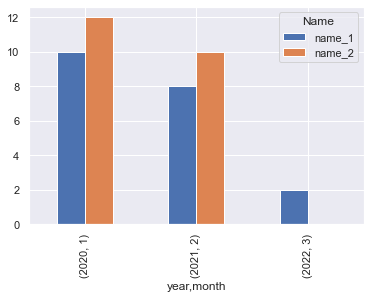
several TOP values
# get top Name
top = df['Name'].value_counts().index[:2]
# filter and reshape
df2 = (df[df['Name'].isin(top)]
.pivot(index=['year', 'month'],
columns='Name',
values='count')
)
# plot
df2.plot.bar()