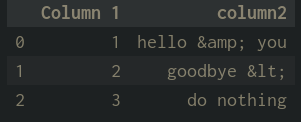
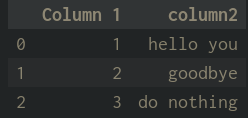
I am only showing an example here. Is there a way to remove all of the special characters? (eg. not just "&" and "<" shown)
CodePudding user response:
I think the following would work with only one pass through the text
re.sub("&[a-zA-Z] ?;","",corpus_of_text)
in a dataframe i think its just (I think...)
cleaned_values = df['column2'].str.replace(re.compile("&[a-zA-Z] ?;"),"")
CodePudding user response:
found this https://gist.github.com/codeboy/5487eeb1c551d59e2366 which does slightly more than you're asking, so i modified it to this:
import re
def parse_text(text, patterns=None):
"""
modified from above github gist
delete all HTML entities
:param text (str): given text
:param patterns (dict): patterns for re.sub
:return str: final text
"""
base_patterns = {"&[rl]dquo;": "",
"&[rl]squo;": "",
" ": "",
"&": ""}
patterns = patterns or base_patterns
final_text = text
for pattern, repl in patterns.items():
final_text = re.sub(pattern, repl, final_text)
return final_text
you can call it like this, assigning to a new column so you can compare the result to the original string:
df["column3"] = df["column2"].apply(parse_text)
please note that the patterns variable is probably not complete, and you may have to augment it based on what you have in your escaped HTML.