I have a numeric vector like this x <- c(1, 23, 7, 10, 9, 2, 4) and I want to group the elements from left to right with the constrain that each group sum must not exceed 25. Thus, here the first group is c(1, 23), the second is c(7, 10) and the last c(9, 2, 4). the expected output is a dataframe with a second column containing the groups:
data.frame(x= c(1, 23, 7, 10, 9, 2, 4), group= c(1, 1, 2, 2, 3, 3, 3))
I have tried different things with cumsum but am not able to kind of dynamically restart cumsum for the new group once the limit sum of 25 for the last group is reached.
CodePudding user response:
In base R you could also use Reduce:
do.call(rbind, Reduce(\(x,y) if((z<-x[1] y) > 25) c(y, x[2] 1)
else c(z, x[2]), x[-1], init = c(x[1], 1), accumulate = TRUE))
[,1] [,2]
[1,] 1 1
[2,] 24 1
[3,] 7 2
[4,] 17 2
[5,] 9 3
[6,] 11 3
[7,] 15 3
Breaking it down:
f <- function(x, y){
z <- x[1] y
if(z > 25) c(y, x[2] 1)
else c(z, x[2])
}
do.call(rbind, Reduce(f, x[-1], init = c(x[1], 1), accumulate = TRUE))
if using accumulate
library(tidyverse)
accumulate(x[-1], f, .init = c(x[1], 1)) %>%
invoke(rbind, .)
[,1] [,2]
[1,] 1 1
[2,] 24 1
[3,] 7 2
[4,] 17 2
[5,] 9 3
[6,] 11 3
[7,] 15 3
CodePudding user response:
You can use the cumsumbinning built-in function from the MESS package:
# install.packages("MESS")
MESS::cumsumbinning(x, 25, cutwhenpassed = F)
# [1] 1 1 2 2 3 3 3
Or it can be done with purrr::accumulate:
cumsum(x == accumulate(x, ~ifelse(.x .y <= 25, .x .y, .y)))
# [1] 1 1 2 2 3 3 3
output
group <- MESS::cumsumbinning(x, 25, cutwhenpassed = F)
data.frame(x= c(1, 23, 7, 10, 9, 2, 4),
group = group)
x group
1 1 1
2 23 1
3 7 2
4 10 2
5 9 3
6 2 3
7 4 3
Quick benchmark:
x<- c(1, 23, 7, 10, 9, 2, 4)
bm <- microbenchmark(
fThomas(x),
fJKupzig(x),
fCumsumbinning(x),
fAccumulate(x),
fReduce(x),
fRcpp(x),
times = 100L,
setup = gc(FALSE)
)
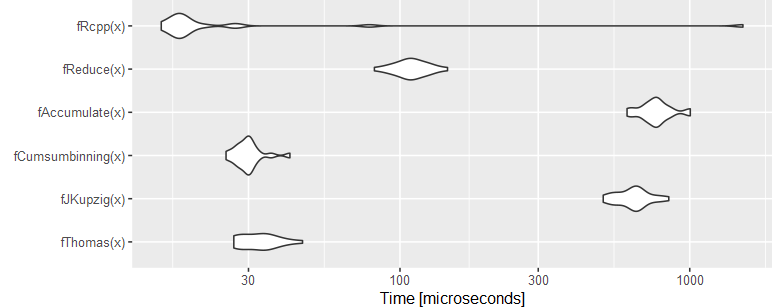
autoplot(bm)
Егор Шишунов's Rcpp is the fastest, closely followed by MESS::cumsumbinning and ThomasIsCoding's function.
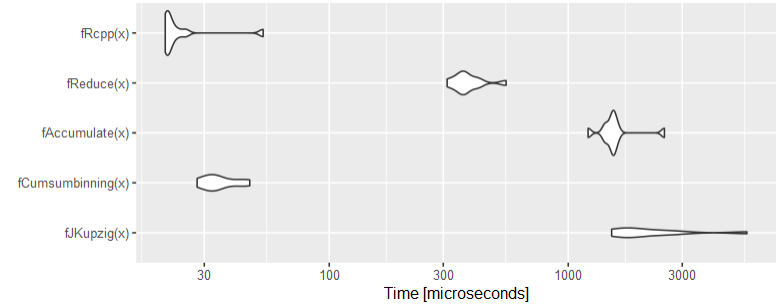
With n = 100, the gap gets bigger but Rcpp and cumsumbinning are still the top choices and the while loop option is no longer efficient (I had to remove ThomasIsCoding's function because it was too long):
x = runif(100, 1, 50)
CodePudding user response:
I think cpp function is the fastest way:
library(Rcpp)
cppFunction(
"IntegerVector GroupBySum(const NumericVector& x, const double& max_sum = 25)
{
double sum = 0;
int cnt = 0;
int period = 1;
IntegerVector res(x.size());
for (int i = 0; i < x.size(); i)
{
cnt;
sum = x[i];
if (sum > max_sum)
{
sum = x[i];
if (cnt > 1)
period;
cnt = 1;
}
res[i] = period;
}
return res;
}"
)
GroupBySum(c(1, 23, 7, 10, 9, 2, 4), 25)
CodePudding user response:
We can try this as a programming practice if you like :)
group <- c()
while (length(x)) {
idx <- cumsum(x) <= 25
x <- x[!idx]
group <- c(group, rep(max(group, 0) 1, sum(idx)))
}
which gives
> group
[1] 1 1 2 2 3 3 3
Another option is using recursion
f <- function(x, res = c()) {
if (!length(x)) {
return(res)
}
idx <- cumsum(x) <= 25
Recall(x[!idx], res = c(res, list(x[idx])))
}
and you will see
> f(x)
[[1]]
[1] 1 23
[[2]]
[1] 7 10
[[3]]
[1] 9 2 4
CodePudding user response:
Here is a solution using base R and cumsum (and lapply for iteration):
id <- c(seq(1, length(x),1)[!duplicated(cumsum(x) %/% 25)], length(x) 1)
id2 <- 1:length(id)
group <- unlist(lapply(1:(length(id)-1), function(x) rep(id2[x], diff(id)[x])))
data.frame(x=x, group=group)
x group
1 1 1
2 23 1
3 7 2
4 10 2
5 9 3
6 2 3
7 4 3