I am looking for an elegant way to achieve updating the dataframe as per below. It contains the answers of a test per student (rows). This data is acquired by reading in an XLSX. The way answers have been recorded changed and I need to revert back to the original format for BI purposes. Different year levels have a different number of columns/questions.
In this df, the correct answers are in the header row, i.e. the Q1 correct answer is "C" (column 3), Q2 column 4 etc.
I need to replace the ticks in the DF with the correct answer as shown in the header for each question/column. I have written a horrible set of loops to do do a quick and dirty but I expect there is a much more elegant way to achieve this with Pandas.
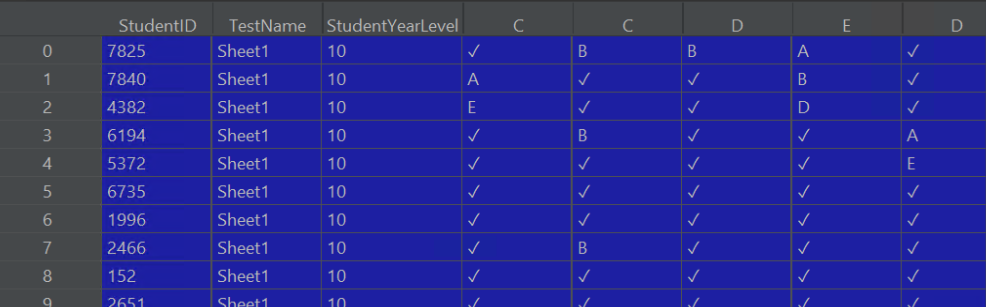
. This dataframe is imported
CodePudding user response:
Use pd.where to mask correct values and then replace what you do not need using columns converted to series
df.where(df != '✓', df.columns.to_series(), axis=1)
Outcome
Name A B D
0 Stud1 A C D
1 Stud2 A B D
2 Stud3 B B A
3 Stud4 C B C
CodePudding user response:
Convert columns names to pd.Series to use as a mapper and use replace to replace each tick mark '✓' with its corresponding column name:
df = df.replace('✓', pd.Series(df.columns, df.columns))
Example: For DataFrame df:
Name A B D
0 Stud1 ✓ C ✓
1 Stud2 ✓ ✓ ✓
2 Stud3 B ✓ A
3 Stud4 C ✓ C
the above code produces:
Name A B D
0 Stud1 A C D
1 Stud2 A B D
2 Stud3 B B A
3 Stud4 C B C