df1 = pd.DataFrame({"DEPTH":[0.5, 1, 1.5, 2, 2.5],
"POROSITY":[10, 22, 15, 30, 20],
"WELL":"well 1"})
df2 = pd.DataFrame({"Well":"well 1",
"Marker":["Fm 1","Fm 2"],
"Depth":[0.7, 1.7]})
Hello everyone. I have two dataframes and I would like to create a new column on df1, for example: df1["FORMATIONS"], with information from df2["Marker"] values based on depth limits from df2["Depth"] and df1["DEPTH"].
So, for example, if df2["Depth"] = 1.7, then all samples in df1 with df1["DEPTH"] > 1.7 should be labelled as "Fm 2" in this new column df1["FORMATIONS"].
And the final dataframe df1 should look like this:
DEPTH POROSITY WELL FORMATIONS
0.5 10 well 1 nan
1 22 well 1 Fm 1
1.5 15 well 1 Fm 1
2 30 well 1 Fm 2
2.5 20 well 1 Fm 2
Anyone could help me?
CodePudding user response:
What you're doing here is transforming continuous data into categorical data. There are many ways to do this with pandas, but one of the better known ways is using 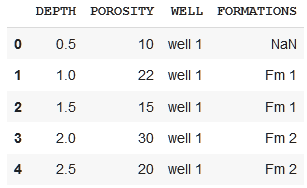
CodePudding user response:
Use pandas.merge_asof:
NB. the columns used for the merge need to be sorted first
pd.merge_asof(df1,
df2[['Marker', 'Depth']].rename(columns={'Marker': 'Formations'}),
left_on='DEPTH', right_on='Depth')
output:
DEPTH POROSITY WELL Formations Depth
0 0.5 10 well 1 NaN NaN
1 1.0 22 well 1 Fm 1 0.7
2 1.5 15 well 1 Fm 1 0.7
3 2.0 30 well 1 Fm 2 1.7
4 2.5 20 well 1 Fm 2 1.7