My dataframe reads
** | Object ID | Top depth | Base Depth|**
1 | obj1 | 1500 | 2000 |
2 | obj1 | 1500 | 1800 |
3 | obj1 | 1900 | 2000 |
4 | obj2 | 900 | 1200 |
5 | obj2 | 1000 | 1200 |
6 | obj3 | 700 | 800 |
I want to drop duplicates but only if it is the same ID with a duplicate top and base depth. for instance, obj1(1) in the first row would be removed as obj1(2) has the same top depth and obj1(3) has the same base depth, obj2 would be left alone because only the base depth is a match.
I was trying to alter the drop duplicates command but I am not sure how to alter it for two true statements i.e. ID & Top Match AND ID & bottom Match
One of my failed attempts:
new_df = old_df.drop_duplicates(subset=[('Object ID', 'Top depth') and ('Object ID', 'Base Depth')]).reset_index(drop=True)
Any help is greatly appreciated.
Edit for further clarification brought to my attention below: The ones I want to drop are combinations of the two others, it encapsulates the depths. Shallowest is the top depth and deepest is the base depth.
Thanks!
CodePudding user response:
Try it like this.
import pandas as pd
df = pd.DataFrame({'Object ID': ['obj1', 'obj1', 'obj1', 'obj2', 'obj2', 'obj3'],
'Top Depth': [1500, 1500, 1900, 900, 1000, 800],
'Base Depth':[2000, 1800, 2000, 1200, 1200, 800]})
df

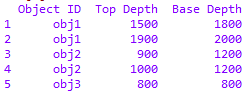
df = df.sort_values('Object ID').drop_duplicates(subset=['Object ID','Top Depth'], keep='last')
df
CodePudding user response:
I think this approach should work.
df = pd.DataFrame({'Object ID': ['obj1', 'obj1', 'obj1', 'obj2', 'obj2', 'obj2','obj2'],
'Top Depth': [1500, 1500, 1900, 900, 1000, 1000, 900],
'Base Depth':[2000, 1800, 2000, 1200, 1200, 800, 1200]})
Object ID Top Depth Base Depth
0 obj1 1500 2000
1 obj1 1500 1800
2 obj1 1900 2000
3 obj2 900 1200
4 obj2 1000 1200
5 obj2 1000 800
6 obj2 900 1200
# drop complete duplicates first
df = df.drop_duplicates(subset=['Object ID','Top Depth','Base Depth'])
# get list of values for Top Depth and Base Depth within the same Object ID
df['Top Depth List'] = df['Object ID'].map(df.groupby('Object ID')['Top Depth'].agg(list).to_dict())
df['Base Depth List'] = df['Object ID'].map(df.groupby('Object ID')['Base Depth'].agg(list).to_dict())
# determine duplicates
df['Duplicate'] = df.apply(lambda x: (x['Base Depth List'].count(x['Base Depth']) > 1) & (x['Top Depth List'].count(x['Top Depth']) > 1), axis=1)
# keep only non-duplicates and the original columns
df = df.loc[~df['Duplicate'], ['Object ID','Top Depth','Base Depth']]
Object ID Top Depth Base Depth
1 obj1 1500 1800
2 obj1 1900 2000
3 obj2 900 1200
5 obj2 1000 800
CodePudding user response:
find duplicates in the first two columns, find duplicates in the first and the last columns. Any thing is duplicate in both of them should be dropped: (Note you should use keep = 'last')
df[~(df.duplicated(subset = ['Object ID','Top Depth'], keep = "last") & df.duplicated(subset = ['Object ID','Base Depth'], keep = "last"))]