The problem:
I have a BigQuery SQL table formatted as such:
| group | users |
|---|---|
| A | 1,2,3 |
| B | 1,5,3 |
| C | 3,6,1 |
| D | 0,1,2 |
I would like to find all possible unique pairs between each group and users, such that the table will be formatted this way:
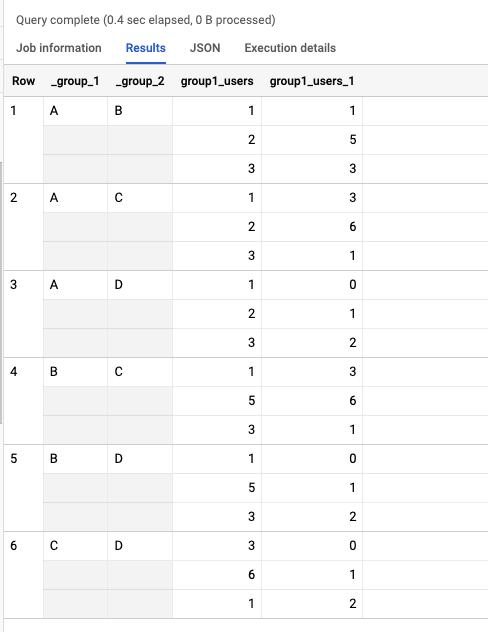
| group1 | group2 | group1_users | group2_users |
|---|---|---|---|
| A | B | 1,2,3 | 1,5,3 |
| A | C | 1,2,3 | 3,6,1 |
| A | D | 1,2,3 | 0,1,2 |
| B | C | 1,5,3 | 3,6,1 |
| B | D | 1,5,3 | 0,1,2 |
| C | D | 3,6,1 | 0,1,2 |
I do not want repeating inverse pairs. So, if pair A,B already exists across columns group1 and group2 respectively, I do not want pair B,A to be an option.
What I've tried:
I'm stumped on how to accomplish this. I've tried modifying code from other posts (