Input Table
| index | income | Education | age1to_20 | pcd |
|---|---|---|---|---|
| 1 | income_1 | Education_0 | 1 | A5009 |
| 2 | income_2 | Education_2 | 1 | A3450 |
| 3 | income_1 | Education_0 | 1 | A5009 |
| 4 | income_3 | Education_1 | 0 | A3450 |
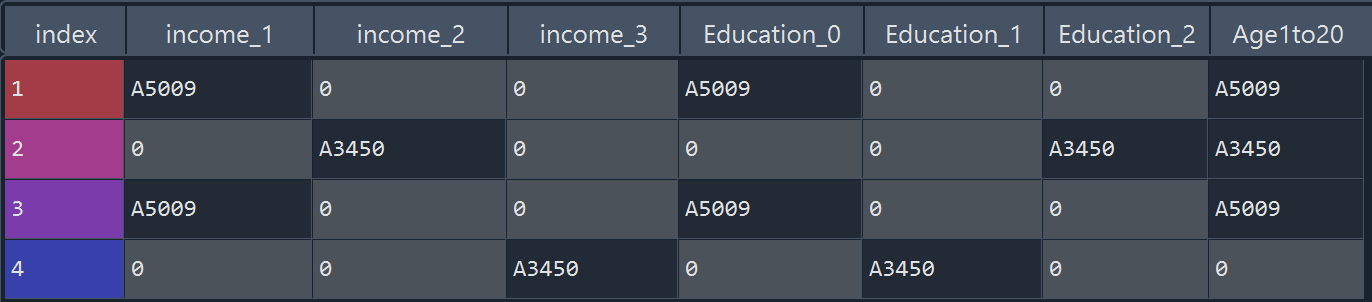
How do I convert this table into
| index | income_1 | income_2 | INCOME_3 | Education_0 | Education_1 | Education_2 | age1to_20 |
|---|---|---|---|---|---|---|---|
| 1 | A5009 | 0 | 0 | A5009 | 0 | 0 | A5009 |
| 2 | 0 | A3450 | 0 | 0 | 0 | A3450 | A3450 |
| 3 | A5009 | 0 | 0 | A5009 | 0 | 0 | A5009 |
| 4 | 0 | 0 | A3450 | 0 | A3450 | 0 | 0 |
UPDATED THE OUTPUT TABLE
CodePudding user response:
Another possible solution:
(pd.concat([
df.pivot(index=['index', 'age1to_20'], columns=['income'], values='pcd'),
df.pivot(index=['index', 'age1to_20'], columns=['Education'], values='pcd')], axis=1)
.fillna(0).reset_index())
Output:
index age1to_20 income_1 income_2 income_3 Education_0 Education_1 Education_2
0 1 1 A5009 0 0 A5009 0 0
1 2 1 0 A3450 0 0 0 A3450
2 3 1 A5009 0 0 A5009 0 0
3 4 0 0 0 A3450 0 A3450 0
EDIT
In case there are a lot of columns to pivot, the following code does that, by iterating over the list of columns to pivot with map:
cols = ['income', 'Education']
(pd.concat(
map(lambda x: df.pivot(
index=['index', 'age1to_20'], columns=x, values='pcd'), cols), axis=1)
.fillna(0).reset_index())
CodePudding user response:
you need to 
Then, in order to change the 1s with the respective pcd value (and drop the column pcd at the end), one can use 
Notes:
An alternative to change the
1s to the respectivepcdand drop the columnpcdwould be to use