I have the following test2.csv file:
id,name,city,country
1,David, Johnson,London,UK,
2,Mary, Gueta,NY,USA,
3,Matthias, Nile,Munich,Germany,
I want to read it into a pandas dataframe. Using this code
df = pd.read_csv('test2.csv')
I get the following df:
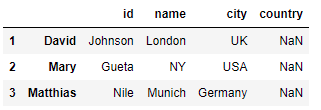
But I want to store the first name and last name together in the column name. id column should store the numbers. city and country should also store the appropriate values.
Thank you in advance!
CodePudding user response:
import csv
file = open(`temp.csv')
csvreader = csv.reader(file)
header = []
header = next(csvreader)
new_rows = []
for row in csvreader:
new_rows.append([row[0], row[1] ',' row[2], row[3], row[4]])
file.close()
df = pd.DataFrame(new_rows, columns =header )
df
CodePudding user response:
There is a useful pattern to distinguish between values, space appears after comma in names, so you can substitute delimiter "," with "|" that is more efficient to avoid this type of confusion
import csv
import pandas as pd
import re
#substitute comma not followed by space for vertical bar in the original file and save it as a new file
with open('test2.csv', 'r') as infile, open('test2_vb.csv', 'w') as outfile:
for line in infile:
line = re.sub(',(?! )', '|', line)
outfile.write(line)
file = open('test2_vb.csv', 'r')
reader = csv.reader(file , delimiter='|')
#load the data into a dataframe
df = pd.DataFrame(reader)
print(df)
this way using a regular expression the file can be corrected (though at the end of a line should not be separator)
CodePudding user response:
You can change 1,David, Johnson,London,UK to 1,"David, Johnson",London,UK then load it using pd.DataFrame