I am trying to scrape 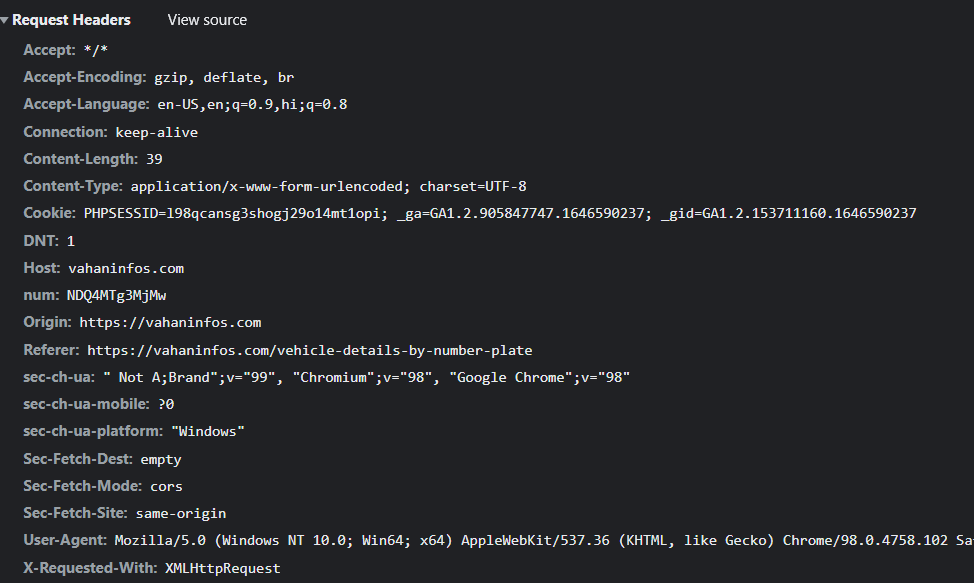
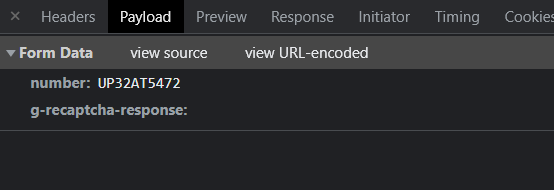
Payload
General Tab
 Thanks in advance
Thanks in advance
CodePudding user response:
This page sends cookies with PHPSESSIONID and in HTML it sends token like this
<script>token = "NDQ4MTg3MjMw"
and it uses JavaScript to get this value and add in headers
num: NDQ4MTg3MjMw,
And server needs PHPSESSIONID and num to send data.
Every connection creates new value in PHPSESSIONID and token - so you could hardcode some values in your code, but session ID can be valid only for a few minutes - and it is better to get fresh values from GET request before POST request.
So you have to use requests.Session to work with cookies and first send GET to https://vahaninfos.com/vehicle-details-by-number-plate to get cookie PHPSESSIONID and HTML with <script>token = "..."
Next you have to get this token from HTML - ie. using regex - and add it as header num: .... in POST request.
It seems other headers are not important - even X-Requested-With.
This page needs to send data as form so you need data=payload instead of data=json.load(payload). And it creates automatically headers Content-Type and Content-Length with correct values.
import requests
import re
session = requests.Session()
# --- GET ---
headers = {
# "User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:97.0) Gecko/20100101 Firefox/97.0",
}
url = "https://vahaninfos.com/vehicle-details-by-number-plate"
res = session.get(url, verify=False)
number = re.findall('token = "([^"]*)"', res.text)[0]
# --- POST ---
headers = {
# "User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:97.0) Gecko/20100101 Firefox/97.0",
# "X-Requested-With": "XMLHttpRequest",
'num': number,
}
payload = {
"number": "UP32AT5472",
"g-recaptcha-response": "",
}
url = "https://vahaninfos.com/getdetails.php"
res = session.post(url, data=payload, headers=headers, verify=False)
print(res.text)
Result:
<tr><td>Registration Number</td><td>:</td><td>UP32AT5472</td></tr>
<tr><td>Registration Authority</td><td>:</td><td>LUCKNOW</td></tr>
<tr><td>Registration Date</td><td>:</td><td>2003-06-06</td></tr>
<tr><td>Chassis Number</td><td>:</td><td>487530</td></tr>
<tr><td>Engine Number</td><td>:</td><td>490062</td></tr>
<tr><td>Fuel Type</td><td>:</td><td>PETROL</td></tr>
<tr><td>Engine Capacity</td><td>:</td><td></td></tr>
<tr><td>Model/Model Name</td><td>:</td><td>TVS VICTOR</td></tr>
<tr><td>Color</td><td>:</td><td></td></tr>
<tr><td>Owner Name</td><td>:</td><td>HARI MOHAN PANDEY</td></tr>
<tr><td>Ownership Type</td><td>:</td><td></td></tr>
<tr><td>Financer</td><td>:</td><td>CENTRAL BANK OF INDIA</td></tr>
<tr><td>Vehicle Class</td><td>:</td><td>M-CYCLE/SCOOTER(2WN)</td></tr>
<tr><td>Fitness/Regn Upto</td><td>:</td><td></td></tr>
<tr><td>Insurance Company</td><td>:</td><td>NATIONAL INSURANCE CO LTD.</td></tr>
<tr><td>Insurance Policy No</td><td>:</td><td>4165465465465</td></tr>
<tr><td>Insurance expiry</td><td>:</td><td>2004-06-05</td></tr>
<tr><td>Vehicle Age</td><td>:</td><td></td></tr>
<tr><td>Vehicle Type</td><td>:</td><td></td></tr>
<tr><td>Vehicle Category</td><td>:</td><td></td></tr>
Now you can use beautifulsoup or lxml (or other module) to get values from HTML.
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, 'html.parser')
for row in soup.find_all('tr'):
cols = row.find_all('td')
key = cols[0].text
val = cols[-1].text
print(f'{key:22} | {val}')
Result:
Registration Number | UP32AT5472
Registration Authority | LUCKNOW
Registration Date | 2003-06-06
Chassis Number | 487530
Engine Number | 490062
Fuel Type | PETROL
Engine Capacity |
Model/Model Name | TVS VICTOR
Color |
Owner Name | HARI MOHAN PANDEY
Ownership Type |
Financer | CENTRAL BANK OF INDIA
Vehicle Class | M-CYCLE/SCOOTER(2WN)
Fitness/Regn Upto |
Insurance Company | NATIONAL INSURANCE CO LTD.
Insurance Policy No | 4165465465465
Insurance expiry | 2004-06-05
Vehicle Age |
Vehicle Type |
Vehicle Category |
EDIT:
After running code few times POST started sending me only values R - maybe it needs some other headers to hide bot (ie. User-Agent), or maybe sometimes it needs to send correct code for ReCaptcha.
At least in Chrome it stops sending R when I set ReCaptha.
But Firefox still send R.
Originally I was using User-Agent from my Firefox and it may remeber it.
EDIT:
If I use User-Agent different then my Firefox then code again gets correct values and Firefox still gets only R.
headers = {
"User-Agent": "Mozilla/5.0",
}
So it seems code may need to use random User-Agent in every request to hide bot.