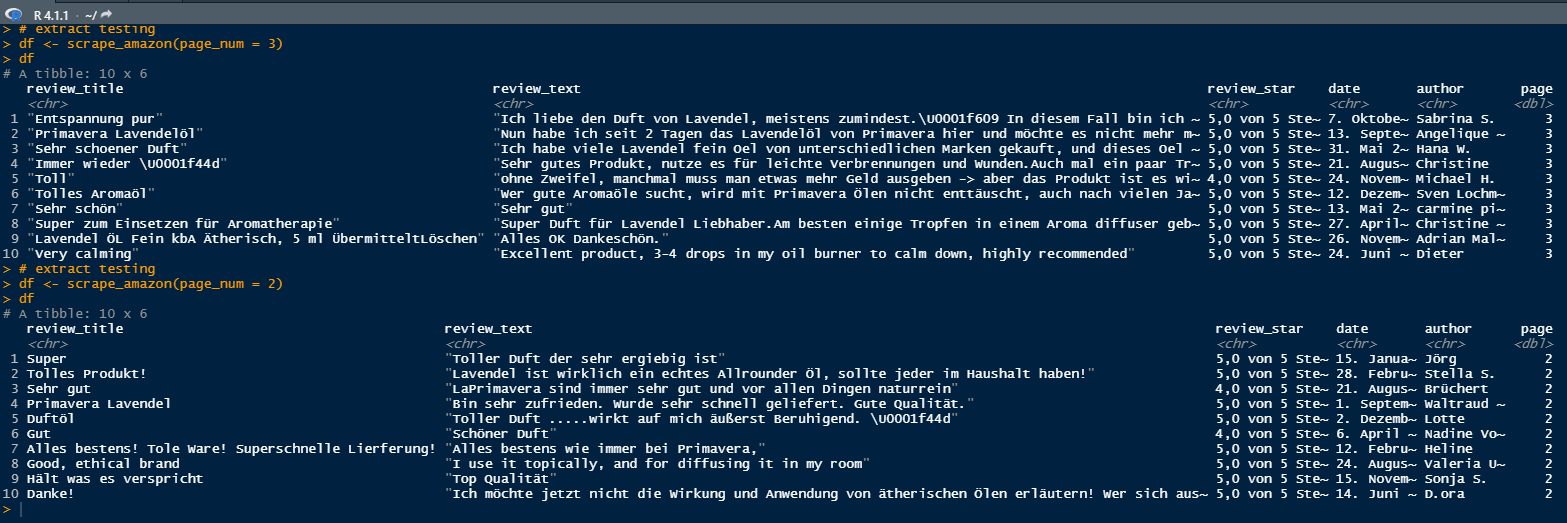
In order to get some interesting data for NLP, I just started to do some basic web scraping in R. My goal is to gather product reviews from amazon, as much as I can. My first basic trials succeeded, but now I am running into an error.
As you can check from the url in my reprex, there are 3 pages of reviews for the product. If I scrape the first and second one, everything works fine. The third page contains a review from a foreign customer.
When I am trying to scrape page three I am getting an error indicating, that my tibble columns do not have compatible sizes. How can I explain this and how to avoid the error?
Also the error disappears, if I delete review_star and review_title from the scrape function.
library(pacman)
pacman::p_load(RCurl, XML, dplyr, rvest)
#### SCRAPE
scrape_amazon <- function(page_num){
url_reviews <- paste0("https://www.amazon.de/Lavendel-ÖL-Fein-kbA-Ätherisch/product-reviews/B00EXBKQDS/ref=cm_cr_getr_d_paging_btm_next_3?ie=UTF8&reviewerType=all_reviews&pageNumber=",page_num)
doc <- read_html(url_reviews)
# Review Title
doc %>%
html_nodes("[class='a-size-base a-link-normal review-title a-color-base review-title-content a-text-bold']") %>%
html_text() -> review_title
# Review Text
doc %>%
html_nodes("[class='a-size-base review-text review-text-content']") %>%
html_text() -> review_text
# Number of stars in review
doc %>%
html_nodes("[data-hook='review-star-rating']") %>%
html_text() -> review_star
# date
date <- doc %>%
html_nodes("#cm_cr-review_list .review-date") %>%
html_text() %>%
gsub(".*on ", "", .)
# author
author <- doc %>%
html_nodes("#cm_cr-review_list .a-profile-name") %>%
html_text()
# Return a tibble
tibble(review_title,
review_text,
review_star,
date,
author,
page = page_num) %>% return()
}
# extract testing
df <- scrape_amazon(page_num = 3)
CodePudding user response:
So, a couple of approaches I generally use in situations concerning listings where some listings may have missing items/differences in html:
- Find a css selector list which returns the listings as an iterable (list of listings). In this case
[id^='customer_review']can be used. If you test this in the browser dev tools you can check the number of matches. This should be a parent node list containing all the items (per listing) you want. - Loop that list within a nested
map_dfr(), data.frame()call and target the various child nodes such that a) you get a dataframe b) you get a nice NA returned for missing items. - Use dev tools F12 to check that the lengths of returned nodeLists, per css selector list, to get an idea of where items may be missing e.g.
Your rating selector against page 3:

which misses the difference in HTML for non-Germany based listings
data-hook="cmps-review-star-rating"
Compare that to testing in advance and re-writing as:

N.B. 1) There is a leading id selector in the list in the image serving to restrict to the same nodeList that we would be iterating over i.e. excluding the Top ve and Top critical review items 2) The html content returned by rvest will be as per the page source rather than the browser rendered content so it is worth then doing a secondary check of your selectors against that content. I typically use Fetch URL within 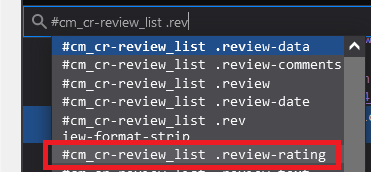
- As shown below, prefer shorter css selector lists, with more stable looking relationships/attributes, to mitigate for changes in html over time
TODO: There are some type conversions you may wish to implement as an immediate item
library(pacman)
pacman::p_load(RCurl, XML, dplyr, rvest, purrr)
#### SCRAPE
scrape_amazon <- function(page_num) {
url_reviews <- paste0("https://www.amazon.de/Lavendel-ÖL-Fein-kbA-Ätherisch/product-reviews/B00EXBKQDS/ref=cm_cr_getr_d_paging_btm_next_3?ie=UTF8&reviewerType=all_reviews&pageNumber=", page_num)
doc <- read_html(url_reviews)
map_dfr(doc %>% html_elements("[id^='customer_review']"), ~ data.frame(
review_title = .x %>% html_element(".review-title") %>% html_text2(),
review_text = .x %>% html_element(".review-text-content") %>% html_text2(),
review_star = .x %>% html_element(".review-rating") %>% html_text2(),
date = .x %>% html_element(".review-date") %>% html_text2() %>% gsub(".*vom ", "", .),
author = .x %>% html_element(".a-profile-name") %>% html_text2(),
page = page_num
)) %>%
as_tibble %>%
return()
}
# extract testing
df <- scrape_amazon(page_num = 3)
# df <- scrape_amazon(page_num = 2)