I have tried to simplify the query to focus on main point only. I have a dataframe with one datetime column and one addtional column val1 as given below .
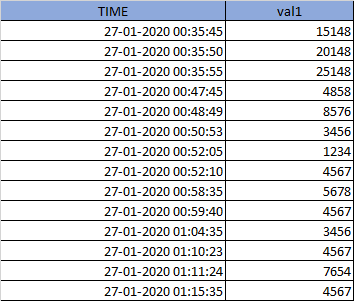
and I also have list of range of time as below
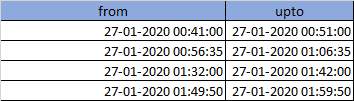
I need a way to remove all the records from the dataframe where "TIME" is between any one of the given ranges. My actual data has 100K records so I am struggling to find an optimized way to perform this action.
Please note, in actual case all the time Ranges are also derived on the go so cant use a logical operators to compare with fix set of time ranges.
Either filter out from the main dataframe or create a copy with required data only, I will be fine with both ways.
Copying above data below for reference.
Range table:
from,upto
'27-01-2020 00:41:00','27-01-2020 00:51:00'
'27-01-2020 00:56:35','27-01-2020 01:06:35'
'27-01-2020 01:32:00','27-01-2020 01:42:00'
'27-01-2020 01:49:50','27-01-2020 01:59:50'
Data table:
TIME,val1
'27-01-2020 00:35:45','15148'
'27-01-2020 00:35:50','20148'
'27-01-2020 00:35:55','25148'
'27-01-2020 00:47:45','4858'
'27-01-2020 00:48:49','8576'
'27-01-2020 00:50:53','3456'
'27-01-2020 00:52:05','1234'
'27-01-2020 00:52:10','4567'
'27-01-2020 00:58:35','5678'
'27-01-2020 00:59:40','4567'
'27-01-2020 01:04:35','3456'
'27-01-2020 01:10:23','4567'
'27-01-2020 01:11:24','7654'
'27-01-2020 01:15:35','4567'
CodePudding user response:
Use Series.between in list comprehension and np.logical_or.reduce for mask, last filter in inverted condition by ~:
df1['TIME'] = pd.to_datetime(df1['TIME'])
df2['upto'] = pd.to_datetime(df2['upto'])
df2['from'] = pd.to_datetime(df2['from'])
zipped = zip(df2['from'], df2['upto'])
m = np.logical_or.reduce([df1['TIME'].between(s, e) for s, e in zipped])
df = df1[~m]
print (df)
TIME val1
0 2020-01-27 00:35:45 '15148'
1 2020-01-27 00:35:50 '20148'
2 2020-01-27 00:35:55 '25148'
6 2020-01-27 00:52:05 '1234'
7 2020-01-27 00:52:10 '4567'
11 2020-01-27 01:10:23 '4567'
12 2020-01-27 01:11:24 '7654'
13 2020-01-27 01:15:35 '4567'