I'm using MariaDB: mysql Ver 15.1 Distrib 10.3.32-MariaDB. The only configuration option I have changed from Ubuntu's default is that I changed innodb_buffer_pool_size = 1G after having some issues with deleting a large number of rows before. I don't have replication set up.
I just inserted roughly 600 million rows into a table. All my tables are InnoDB except, of course, the system tables. The table (edges) is really simple; two integer columns which form a composite primary key. The insertion process took approximately 4 days and completed successfully (it was an INSERT INTO edges SELECT some, columns FROM a INNER JOIN b ON a.column = b.foreign_key).
During the INSERT, I had an idea of how many rows would be inserted, so to get a rough idea of progress I would start a separate mysql query prompt and run SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED followed by SELECT COUNT(*) FROM the_table and find how many rows have been inserted so far. I also ran SHOW PROCESSLIST which just shows how long it's been running. I was able to figure out a rough estimate of how long things were going to take by doing some math: taking the number of seconds the query had been running from SHOW PROCESSLIST and extrapolating that based on the rough number of rows inserted so far and how many rows I thought would result.
Here is where I am a bit lost: Once the prompt where I inserted the rows returned successfully, the load average spiked higher than it was during the INSERT. I see that it's all because of IO from MySQL.
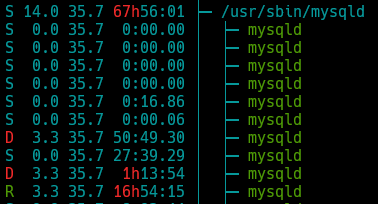
SHOW PROCESSLIST doesn't really say anything, even though clearly some processes are running on several different threads as indicated by htop.
The closest I've gotten to figure out what's going on is SHOW ENGINE INNODB STATUS. Here's some log-related data:
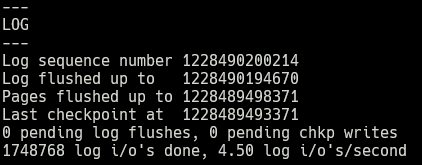
It seems like the large numbers keep increasing, but I am confused because it says 0 pending log flushes, yet Log flushed up to keeps increasing, and no queries at all are running.
Here is the INSERT BUFFER AND ADAPTIVE HASH INDEX, but
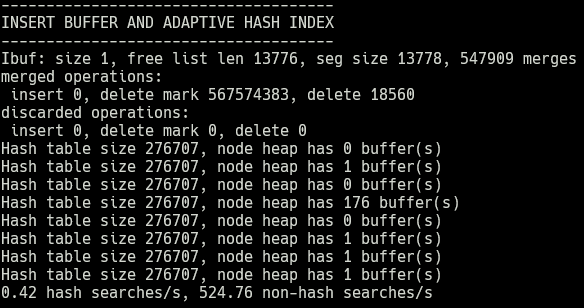
Here's the output in gist form: https://gist.github.com/hut8/3508c901e6ebfaab65656b8ae3c32ae3
CREATE TABLE for the table into which insertion is happening:
CREATE TABLE `edges` (
`source_page_id` int(8) unsigned NOT NULL,
`dest_page_id` int(8) unsigned NOT NULL,
PRIMARY KEY (`source_page_id`,`dest_page_id`))
The insert statement was:
INSERT INTO edges (source_page_id, dest_page_id)
SELECT pl.pl_from, v.page_id
FROM pagelinks pl
INNER JOIN vertexes v
ON v.page_title = pl.pl_title;
The two tables that are the source for the data in that join look like:
CREATE TABLE `pagelinks` (
`pl_from` int(8) unsigned NOT NULL DEFAULT 0,
`pl_namespace` int(11) NOT NULL DEFAULT 0,
`pl_title` varbinary(255) NOT NULL DEFAULT '',
`pl_from_namespace` int(11) NOT NULL DEFAULT 0
)ENGINE=InnoDB DEFAULT CHARSET=binary ROW_FORMAT=COMPRESSED;
CREATE TABLE `vertexes` (
`page_id` int(8) unsigned NOT NULL DEFAULT 0,
`page_title` varbinary(255) NOT NULL DEFAULT '',
PRIMARY KEY (`page_id`),
KEY `page_title_index` (`page_title`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
There are no indexes on pagelinks as you can see.
MariaDB [wiki]> explain SELECT pl.pl_from, v.page_id
FROM pagelinks pl
INNER JOIN vertexes v
ON v.page_title = pl.pl_title\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: pl
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 676208507
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: v
type: ref
possible_keys: page_title_index
key: page_title_index
key_len: 257
ref: wiki.pl.pl_title
rows: 1
Extra: Using index
Basically, I am very confused as to what the server is actually doing, and how long it will take to do it. Can anyone point me in the right direction? Again, I am only wondering about what happens after the INSERT appears to have completed. Many thanks in advance.
CodePudding user response:
InnoDB is designed to postpone costly I/O work in various ways. When you write changes to rows in a transaction, it only modifies pages in RAM -- in the buffer pool. But it also logs the change in the InnoDB redo log on disk, so it can recover if a crash occurs. Then the pages in the buffer pool are flushed to disk some time later.
But if you are writing 600 million rows, you're certainly going to fill up the redo log over and over. When that happens, InnoDB is forced to flush modified pages from RAM to disk immediately.
In addition to that, building secondary indexes is postponed further. That's the "Insert buffer" noted in the innodb status. So a transaction is committed, data pages are flushed later, and secondary index pages are "merged" later still.
Basically, there's a lot of cleanup work to do after you do a lot of inserts/updates. That's why you continue to see I/O load for some time after you think your inserts are done.
The InnoDB design is sensible if the high write rate is sporadic. It tries to react very quickly, and defer some of the work. Hoping it can "catch up" before you have another surge of writes. But you're trying to do a four-day long surge, so InnoDB ends up falling further and further behind. Once things quiet down, it has to do a great deal of flushing and index merges before it's truly done.
How can you monitor progress? The means to do that is not developed well. Normally you don't have to monitor it. You can query the innodb metrics this way:
SELECT * FROM INFORMATION_SCHEMA.INNODB_METRICS WHERE NAME LIKE '%ibuf%';
But it seems that the insert buffer monitor is disabled by default (all the ibuf-related metrics show status: disabled in my MySQL 8.0 instance). Read https://dev.mysql.com/doc/refman/8.0/en/innodb-information-schema-metrics-table.html to learn how to enable specific innodb monitors.
Interpreting the results of these innodb metrics is a little mysterious. You can read https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html but you will have to "read between the lines" quite a bit to understand what the numbers represent. You may even need to read some of the source code of the InnoDB storage engine.
CodePudding user response:
Run SHOW PROCESSLIST with suitable permissions -- you can see only the commands that you are allowed to see.
Load average and I/O may vary for a lot of reasons. UNIQUE indexes are checked and updated on the fly; non-unique indexes are inserted later (cf "change buffering"). This may explain the spike after the Insert returned. It's not something to worry about.
How tiny is your server (or VM)? 1G for the buffer pool implies that there will be a lot of I/O for 600M rows.
"Progress bars" are only partially viable.
Will you be reloading the 600M rows frequently? If so, we can discuss better ways. Is this a complete replacement of a table? Or are most rows the same? Or what?
A big cost in inserting 600M rows at once is the need to be read to ROLLBACK the entire transaction. Once it is COMMITted, all the "rollback" stuff needs to be cleaned up. This may be part of your post-commit spike.
If other connections are touching the table, this big Insert is likely to run slower than if they were not touching it.
I will only periodically replace all the rows and will never update them. I am getting the data directly from Wikipedia's dumps and don't need the most up to date data. I could insert with no primary key and then build it later, or just add an index on the first column because that's all I will query by.
Assuming you are getting a CSV file, do it this way:
CREATE TABLE new_tbl ...-- With thePRIMARY KEYin place.- Use the OS's sort to sort the csv file in PK order.
LOAD DATA INFILE ...intonew_tbl.RENAME TABLE tbl TO old_tbl, new_tbl TO tbl;DROP TABLE tbl;
Notes:
- Swapping is terrible for performance; since you have only 2GB of RAM, lower
innodb_buffer_pool_sizeto only 500M. - You probably need to be using utf8mb4 everywhere. (But I guess that does not matter, since I see
VARBINARY. ROW_FORMAT=COMPRESSEDmay not be worth it.- Steps 1,4,5 are virtually instantaneous.
- The sort may be the fastest possible way to do the sort.
- By having the data pre-sorted, populating the PK will be virtually free.
- There will be essentially no downtime because step 4 is very fast.
- No need for "progress bar"
- Since the load is essentially "sequential", it does not matter that the buffer_pool is much less than the table size.
- By building a fresh table, there is less "Rollback/undo/redo/etc" stuff to deal with.
- "There are no indexes on pagelinks as you can see." -- No index is needed since it will scan the table entirely anyway.
Chunking the INSERT...SELECT:
Assuming that the 4-day Insert is really being slowed down by that JOIN, Let's chunk up the query. That is, let's walk through pagelinks 1000 rows at a time, then COMMIT. That will involve 1000 lookups in vertexes 1000 times (nearly 1000 16KB blocks fetched = 16MB). This periodic Commit helps soften the overhead discussed by Bill. See this for tips on chunking: http://mysql.rjweb.org/doc.php/deletebig#deleting_in_chunks
CodePudding user response:
I suspect 98% of the Select's JOIN is due to I/O that cannot be cached. It would take a lot more RAM to provide a big enough buffer_pool to 'solve' that problem.
So, here's Plan B:
Add another column to vertexes (after loading):
CREATE TABLE `vertexes` (
`page_id` int(8) unsigned NOT NULL DEFAULT 0,
`page_title` varbinary(255) NOT NULL DEFAULT '',
title_hash BINARY(16) NOT NULL, -- MD5 of the title
PRIMARY KEY (`page_id`),
KEY `page_title_index` (`page_title`),
INDEX(title_hash, page_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
Similarly, have the title_hash in the other table. Now, change the JOIN to act on title_hash instead of page_title -- a much smaller value. Hence, it caches better.
PS. MariaDB 10.3 may have a mechanism for doing that hashing automatically.
But, that may not be good enough, so here's Plan C:
Let's arrange for the JOIN to act on the two tables in the "same order". (This starts from the original tables, no hashing.) That is:
SELECT pl.pl_from, v.page_id FROM pagelinks pl INNER JOIN vertexes v ON v.page_title = pl.pl_title;
If we have these two pairs sorted, the JOIN will work like a zipper:
(pl_title, pl_from)
(page_title, page_id)
That can easily be done by having
INDEX(pl_title, pl_from)
INDEX(page_title, page_id) -- This already exists.
Now, the JOIN will (should) use those two indexes, both of which are in alphabetical order, thereby making the work very efficient (wrt I/O).
Summary of Plan C:
ALTER TABLE pagelinks ADD INDEX(page_title, page_id);Add
ORDER BY pl_titleto theSELECTto make them go in the same order.Leave off the PK on
edgesduring the Insert; instead doALTER TABLE edges ADD PRIMARY KEY(source_page_id, dest_page_id)after loading the table.