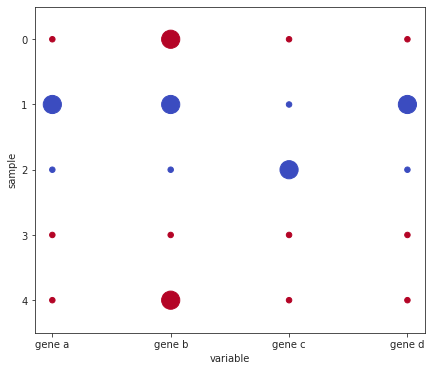
I'd like to use matplotlib.pyplot.scatter to create a scatter plot similar to the picture below from data in a dataframe with a header that is formatted similar to the table here where all the points for a given sample are colored based on the label in the first column of the data and a point is only plotted for each gene with a value of 1 - no point for the genes with a 0 value:
| label | gene a | gene b | gene c | gene d |
|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |

Note: my sample data does not match my sample scatter plot output.
CodePudding user response:
After melting your dataframe to a long format you can draw a matrix with seaborn's 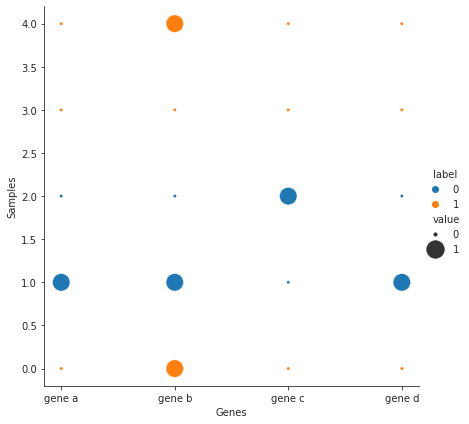
With the melted dataframe you can access plt.scatter directly from pandas but I think you have to add your own custom legend for the labels.
df.plot(x='variable', y='sample', s=(df.value 0.1) * 300, kind='scatter',
ylim=[df['sample'].max() .5, df['sample'].min()-.5], # uncomment to flip y-axis
figsize=(7,6), c='label', cmap='coolwarm', colorbar=False
);