my question is: I have two Dataframes:
Dataframe 1:
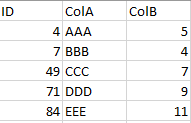
Dataframe 2:
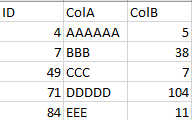
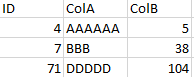
If you notice, Dataframe 2 has some updated values and I want to create a new Dataframe that has only theses updated values, no matter which column had its updated value.
Desired Dataframe:
CodePudding user response:
Let's make sure we have the right dataframes:
In [270]: df1
Out[270]:
a b
0 aaa 5
1 bbb 4
2 ccc 7
3 ddd 9
4 eee 11
In [271]: df2
Out[271]:
a b
0 aaaaa 5
1 bbb 38
2 ccc 7
3 ddddd 104
4 eee 11
We want df2's values, so left join:
In [272]: df = df2.set_index('a').join(df1.set_index('a'), how='left', rsuffix="_r")
In [273]: df
Out[273]:
b b_r
a
aaaaa 5 NaN
bbb 38 4.0
ccc 7 7.0
ddddd 104 NaN
eee 11 11.0
We only care about when the values differ:
In [274]: df = df[df.b != df.b_r]
In [275]: df
Out[275]:
b b_r
a
aaaaa 5 NaN
bbb 38 4.0
ddddd 104 NaN
We no longer need df1's values:
In [276]: df = df.drop(columns=['b_r'])
In [277]: df
Out[277]:
b
a
aaaaa 5
bbb 38
ddddd 104
CodePudding user response:
After some work, I came with a solution. I don't know if it is the best way to do it:
This is Dataframe 1:
In [4]: df1
Out[4]:
id ColA ColB ColC
0 4 AAA 5 Test 1
1 7 BBB 4 Test 2
2 49 CCC 7 Test 3
3 71 DDD 9 Test 4
4 84 EEE 11 Test 5
And this is Dataframe 2:
In [5]: df2
Out[5]:
Out[5]:
id ColA ColB ColC
0 4 AAAAA 5 Test 1
1 7 BBB 38 Test 2
2 49 CCC 7 Test 3
3 71 DDDDD 104 Test 4
4 84 EEE 11 Test_5
5 102 FFF 23 Test 6
So, I want to create a new Dataframe that only has items that exists only in Dataframe 2:
In [6]: df_unique = df2[~df2.id.isin(df1.id)]
In [7]: df_unique
Out[7]:
id ColA ColB ColC
5 102 FFF 23 Test 6
And then I remove these items from Dataframe 2 so that it has only the items that were modified:
In [8]: df2 = df2[~df2.id.isin(df_unique.id)]
In [9]: df2
Out[9]:
id ColA ColB ColC
0 4 AAAAA 5 Test 1
1 7 BBB 38 Test 2
2 49 CCC 7 Test 3
3 71 DDDDD 104 Test 4
4 84 EEE 11 Test_5
Finally, I create a new Dataframe that only has the items modified compared to Dataframe 1:
In [10]: df_merged = pd.merge(df2, df1, how='outer',
indicator=True).query('_merge=="left_only"').drop('_merge', axis=1)
In [11]: df_merged
Out[11]:
id ColA ColB ColC
0 4 AAAAA 5 Test 1
1 7 BBB 38 Test 2
3 71 DDDDD 104 Test 4
4 84 EEE 11 Test_5