I have the following dataframe:
import pandas as pd
#Create DF
d = {
'Country': ['USA','USA','AUS','AUS','AUS','UK','UK'],
'poulation_k':[200,250,150,120,350,800,600,],
}
df = pd.DataFrame(data=d)
df
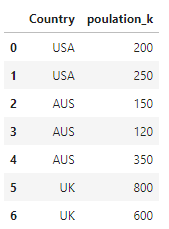
I would like to sort the rows by poulation where Country = AUS but maintaining their order in the overall dataframe:
So my expected output will be:
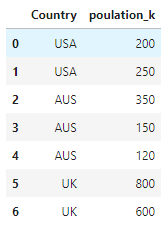
I would also like to do it by the other countries however i would like to do it on a manual basis - i.e i would like the function to specify the Country name. Any help would be fantastic! Thanks
UPDATE:
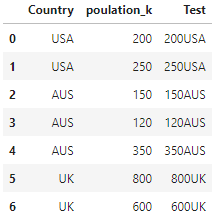
Edit, i negleted to put in that my dataframes consist of other columns as well. so the example should be:
import pandas as pd
#Create DF
d = {
'Country': ['USA','USA','AUS','AUS','AUS','UK','UK'],
'poulation_k':[200,250,150,120,350,800,600,],
}
df = pd.DataFrame(data=d)
df['Test'] = df.poulation_k.astype(str) df.Country
df
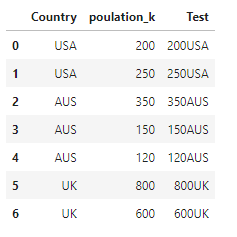
With the expected output of the function to sort AUS being:
CodePudding user response:
def func(country):
sub_df = df[df['Country']==country]
idx_i = sub_df.index
idx_f = sub_df.sort_values('poulation_k', ascending=False).index
return df.rename(dict(zip(idx_f, idx_i))).sort_index()
func('AUS')
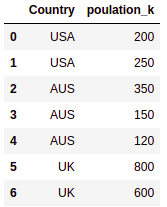
My solution modifies the index so it will work no matter how many columns you have in your dataframe.
CodePudding user response:
As you only reorder one column, you can do it simply:
df.loc[df['Country'] == 'AUS', 'poulation_k'] = np.sort(
df.loc[df['Country'] == 'AUS', 'poulation_k'].values)
It gives as expected:
Country poulation_k
0 USA 200
1 USA 250
2 AUS 120
3 AUS 150
4 AUS 350
5 UK 800
6 UK 600