So, I have a panel-time series dataset, but since for each ID the starting date is different, i created an additional variable t that is a count variable, t=0, 1, 2, 3, .... and the end date is all different. Using the data, I want to plot:
- a multiline graph where x-axis is "t" =0,1,2,3... and y-axis is "growth" for all IDs
- additionally, if i want to have x-axis start from t=1 and omit of t=0?
thank you!
Current table:
ID date growth t
x1a 1/1/2018 1.2 0
x1a 2/1/2018 1 1
x1a 3/1/2018 3 2
x1a 4/1/2018 2 3
x1a 5/1/2018 0.9 4
z8d 3/1/2018 0.7 0
z8d 3/2/2018 1 1
z8d 3/3/2018 0.8 2
z8d 3/4/2018 0.6 3
z8d 3/5/2018 2.3 4
z8d 3/6/2018 1.7 5
z8d 3/7/2018 1 6
z8d 3/8/2018 2.1 7
j2u 1/1/2020 0.9 0
j2u 1/2/2020 0.8 1
j2u 1/3/2020 1.3 2
j2u 1/4/2020 1.4 3
j2u 1/5/2020 2 4
j2u 1/6/2020 1.4 5
.. .. .. ..
CodePudding user response:
You don't need the "t" column, you could use the index for that. To plot a line for each id, you could groupby id, then iterate over the groups and plot. Here is an example of how to do that:
from io import StringIO
import matplotlib.pyplot as plt
import pandas as pd
data = """ID date growth t
x1a 1/1/2018 1.2 0
x1a 2/1/2018 1 1
x1a 3/1/2018 3 2
x1a 4/1/2018 2 3
x1a 5/1/2018 0.9 4
z8d 3/1/2018 0.7 0
z8d 3/2/2018 1 1
z8d 3/3/2018 0.8 2
z8d 3/4/2018 0.6 3
z8d 3/5/2018 2.3 4
z8d 3/6/2018 1.7 5
z8d 3/7/2018 1 6
z8d 3/8/2018 2.1 7
j2u 1/1/2020 0.9 0
j2u 1/2/2020 0.8 1
j2u 1/3/2020 1.3 2
j2u 1/4/2020 1.4 3
j2u 1/5/2020 2 4
j2u 1/6/2020 1.4 5"""
df = pd.read_csv(StringIO(data), sep='\s ')
df['date'] = pd.to_datetime(df['date'])
for id_, df in df.groupby(by='ID'):
df.sort_values(by='date', inplace=True)
df.reset_index(drop=True, inplace=True)
plt.plot(df.index 1, df['growth'], label=id_)
plt.legend()
plt.xlabel('Index')
plt.ylabel('Growth')
plt.show()
CodePudding user response:
You can reshape your data into a form that makes it easy for pandas to plot them:
from io import StringIO
import matplotlib.pyplot as plt
import pandas as pd
data = """ID date growth t
x1a 1/1/2018 1.2 0
x1a 2/1/2018 1 1
x1a 3/1/2018 3 2
x1a 4/1/2018 2 3
x1a 5/1/2018 0.9 4
z8d 3/1/2018 0.7 0
z8d 3/2/2018 1 1
z8d 3/3/2018 0.8 2
z8d 3/4/2018 0.6 3
z8d 3/5/2018 2.3 4
z8d 3/6/2018 1.7 5
z8d 3/7/2018 1 6
z8d 3/8/2018 2.1 7
j2u 1/1/2020 0.9 0
j2u 1/2/2020 0.8 1
j2u 1/3/2020 1.3 2
j2u 1/4/2020 1.4 3
j2u 1/5/2020 2 4
j2u 1/6/2020 1.4 5"""
df = pd.read_csv(StringIO(data), sep='\s ')
df['date'] = pd.to_datetime(df['date'])
#the actual plotting starts here
#reshape your data for the plot from long to wide format
df_plot = pd.pivot(df, index="t", columns="ID", values="growth")
#renumber the index
df_plot.index = 1
#let pandas matplotlib wrapper do the plotting
df_plot.plot.line()
plt.show()
Sample output:
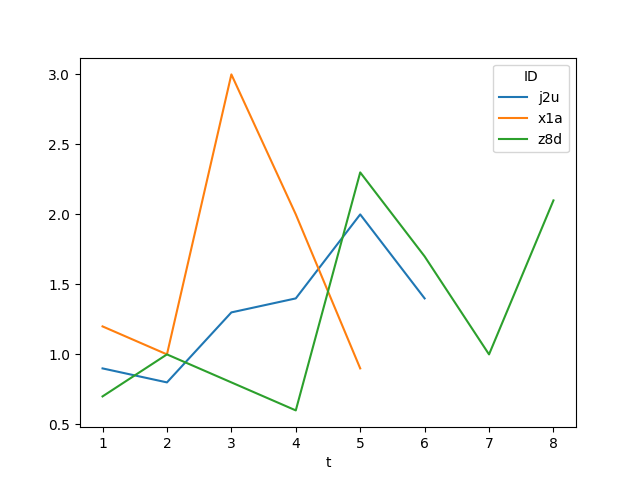
Disclaimer: The sample data import is shamelessly copied from Leonardo's answer.