I feel like there is probably a better way to do this in tidyverse than a for-loop. Start with a standard tibble/dataframe, and make a list where the name of the list elements are the unique values of one column (group_by?) and the list elements are all the values of another column.
my_data <- tibble(list_names = c("Ford", "Chevy", "Ford", "Dodge", "Dodge", "Ford"),
list_values = c("Ranger", "Equinox", "F150", "Caravan", "Ram", "Explorer"))
# A tibble: 6 × 2
list_names list_values
<chr> <chr>
1 Ford Ranger
2 Chevy Equinox
3 Ford F150
4 Dodge Caravan
5 Dodge Ram
6 Ford Explorer
This is the desired output:
desired_output <- list(Ford = c("Ranger", "F150", "Explorer"),
Chevy = c("Equinox"),
Dodge = c("Caravan", "Ram"))
$Ford
[1] "Ranger" "F150" "Explorer"
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
It can be accomplished with a for-loop but I bet there is a tidyverse function that makes it more simple/faster, etc.
desired_output <- list()
for(i in seq_along(my_data$list_names)) {
entry <- my_data %>%
filter(list_names == my_data$list_names[i]) %>%
pull(list_values)
desired_output[[my_data$list_names[i]]] <- entry
}
CodePudding user response:
We can use split
with(my_data, split(list_values,
factor(list_names, levels = unique(list_names))))
$Ford
[1] "Ranger" "F150" "Explorer"
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
Or with unstack
unstack(my_data, list_values ~ list_names)
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
$Ford
[1] "Ranger" "F150" "Explorer"
CodePudding user response:
Here is another option (though a little more verbose) using group_modify and deframe from tidyverse.
library(tidyverse)
my_data |>
group_by(list_names) |>
group_modify(\(x, ...) tibble(res = list(deframe(x)))) |>
deframe()
Or another option could be to use summarise then again use deframe:
my_data %>%
group_by(list_names) %>%
summarise(named_vec = list(list_values)) %>%
deframe()
Output
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
$Ford
[1] "Ranger" "F150" "Explorer"
Benchmark
I was curious to see what is fastest of the answers here, and definitely looks like split by @akrun is by far the fastest, followed by unstack.
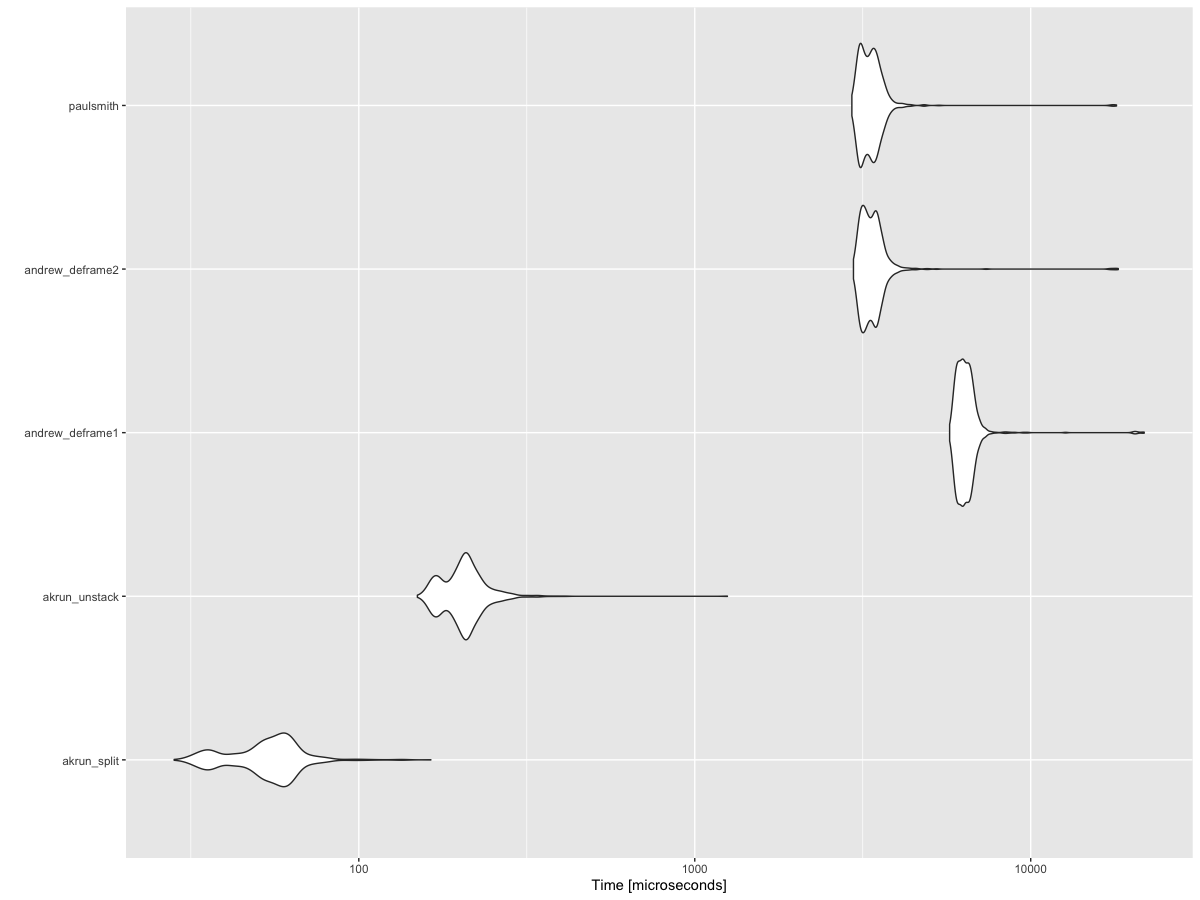
bm <- microbenchmark::microbenchmark(
akrun_split = with(my_data, split(list_values,
factor(list_names, levels = unique(list_names)))),
akrun_unstack = unstack(my_data, list_values ~ list_names),
andrew_deframe1 = my_data |>
group_by(list_names) |>
group_modify(\(x, ...) tibble(res = list(deframe(x)))) |>
deframe(),
andrew_deframe2 = my_data %>%
group_by(list_names) %>%
summarise(named_vec = list(list_values)) %>%
deframe(),
paulsmith = my_data %>%
group_by(list_names) %>%
summarise(list_values = list(list_values)) %>%
{set_names(.$list_values, .$list_names)},
times=1000L
)
CodePudding user response:
Another possible solution:
library(tidyverse)
my_data <- tibble(list_names = c("Ford", "Chevy", "Ford", "Dodge", "Dodge", "Ford"),
list_values = c("Ranger", "Equinox", "F150", "Caravan", "Ram", "Explorer"))
my_data %>%
group_by(list_names) %>%
summarise(list_values = list(list_values)) %>%
{set_names(.$list_values, .$list_names)}
#> $Chevy
#> [1] "Equinox"
#>
#> $Dodge
#> [1] "Caravan" "Ram"
#>
#> $Ford
#> [1] "Ranger" "F150" "Explorer"
CodePudding user response:
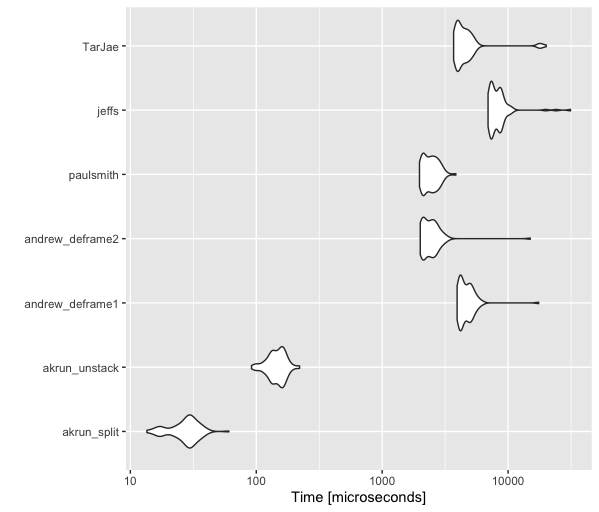
Just for fun, added benchmarks with my for-loop and TarJae's answer.
bm <- microbenchmark::microbenchmark(
akrun_split = with(my_data, split(list_values,
factor(list_names, levels = unique(list_names)))),
akrun_unstack = unstack(my_data, list_values ~ list_names),
andrew_deframe1 = my_data |>
group_by(list_names) |>
group_modify(\(x, ...) tibble(res = list(deframe(x)))) |>
deframe(),
andrew_deframe2 = my_data %>%
group_by(list_names) %>%
summarise(named_vec = list(list_values)) %>%
deframe(),
paulsmith = my_data %>%
group_by(list_names) %>%
summarise(list_values = list(list_values)) %>%
{set_names(.$list_values, .$list_names)},
jeffs = {
desired_output <- list()
for(i in seq_along(my_data$list_names)) {
entry <- my_data %>%
filter(list_names == my_data$list_names[i]) %>%
pull(list_values)
desired_output[[my_data$list_names[i]]] <- entry
}
desired_output},
TarJae = my_data %>%
group_by(list_names) %>%
mutate(list_values= paste(list_values, collapse = ", ")) %>%
slice(1) %>%
group_split() %>%
setNames(sort(unique(my_data$list_names))) %>%
map(., dplyr::pull, -list_names) %>%
map(., ~str_split(.x, ", ")[[1]] ),
times=100L
)
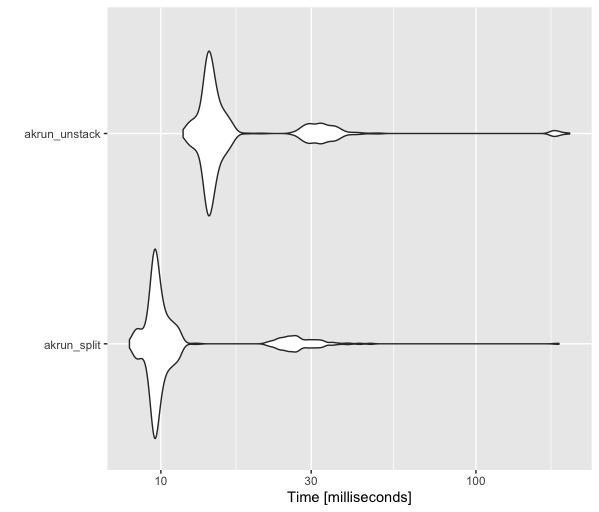
I also ran benchmarks with a larger data set on the two fastest options (from Akrun).
library(nycflights13)
my_data <- nycflights13::flights %>%
select(list_names = carrier, list_values = flight)
CodePudding user response:
Update II: Changed tibble output to vector outouput. Thanks to Jeff Parker!
Update due to Jeff Parker's comment (please see comments). I now updated the code. The issue was setting Names as unsorted, after using sort we can use setNames correctly. Then I added map to apply dplyrs select to remove first column in each dataframe:
library(dplyr)
library(purrr)
my_data %>%
group_by(list_names) %>%
mutate(list_values= paste(list_values, collapse = ", ")) %>%
slice(1) %>%
group_split() %>%
setNames(sort(unique(my_data$list_names))) %>%
map(., dplyr::pull, -list_names) %>%
map(., ~str_split(.x, ", ")[[1]] )
$Chevy
[1] "Equinox"
$Dodge
[1] "Caravan" "Ram"
$Ford
[1] "Ranger" "F150" "Explorer"