I created a scraper, but I keep struggling with one part: getting the keywords associated with a movie/tv-show title.
I have a df with the following urls
keyword_link_list = ['https://www.imdb.com/title/tt7315526/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11723916/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt7844164/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt2034855/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11215178/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt10941266/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt13210836/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt0913137/keywords?ref_=tt_ql_sm']
df = pd.DataFrame({'keyword_link':keyword_link_list})
print(df)
Then, I like the loop through the column keyword_link, get all the keywords, and add them to a dictionary. I managed to get all the keywords, but I do not manage to add them to a dictionary. It seems like a simple problem, but I'm not seeing what I'm doing wrong (after hours of struggling). Many thanks in advance for your help!
# Import packages
import requests
import re
from bs4 import BeautifulSoup
import bs4 as bs
import pandas as pd
# Loop through column keyword_link and get the keywords for each link
keyword_dicts = []
for index, row in df.iterrows():
keyword_link = row['keyword_link']
print(keyword_link)
headers = {"Accept-Language": "en-US,en;q=0.5"}
r=requests.get(keyword_link, headers=headers)
html = r.text
soup = bs.BeautifulSoup(html, 'html.parser')
elements = soup.find_all('td', {'class':"soda sodavote"})
for element in elements:
for keyword in element.find_all('a'):
keyword = keyword['href']
keyword = re.sub(r'\/search/keyword\?keywords=', '', keyword)
keyword = re.sub(r'\?item=kw\d ', '', keyword)
print(keyword)
keyword_dict = {}
keyword_dict['keyword'] = keyword
keyword_dicts.append(keyword_dict)
print(keyword_dicts)
Update
After running the definition, I get the following error:
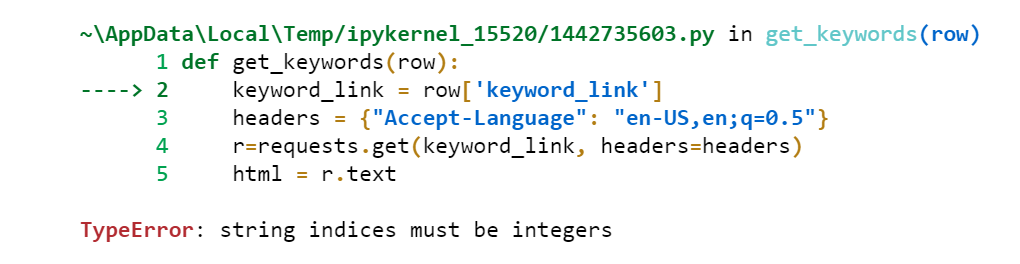
CodePudding user response:
The problem with your code is that you're not saving the keywords in the loop. Also, instead of iterating over dataframe rows, create a function that does what you want and apply it on keyword_link column.
def get_keywords(row):
keyword_link = row['keyword_link']
headers = {"Accept-Language": "en-US,en;q=0.5"}
r=requests.get(keyword_link, headers=headers)
html = r.text
soup = bs.BeautifulSoup(html, 'html.parser')
elements = soup.find_all('td', {'class':"soda sodavote"})
keyword_dict = {'keyword':[]}
# ^^^ declare the dict here
for element in elements:
for keyword in element.find_all('a'):
keyword = keyword['href']
keyword = re.sub(r'\/search/keyword\?keywords=', '', keyword)
keyword = re.sub(r'\?item=kw\d ', '', keyword)
if keyword:
keyword_dict['keyword'].append(keyword)
# ^^^ move this inside the loop
return keyword_dict
However, it might be better to store list of keywords since the 'keyword' key is really doing nothing here.
Anyway, then you can use it as
df[keywords] = df['keyword_link'].apply(get_keywords)
Now, if you need a list of the keyword dictionaries, you can do
keyword_dicts = df[keywords].tolist()
CodePudding user response:
Note: cause expected output is not that clear and could be improved, this example deals with operating on your list only. you can use the output to create a dataframe, lists, ...
What happens?
Your dictionary is defined right behind the loop - You won't get any information to store and your list just contains [{'keyword': ''}]
How to fix?
Append your dictionary while iterating over the keywords.
Alternativ approach:
However, it do not need a dataframe and only one line to get your keywords:
keywords = [e.a.text for e in soup.select('[data-item-keyword]')]
In following example I come up with some variations on how and what could be stored:
Store just the keywords separated by whitespace:
'keywords1':keywords
Store same keywords separated by "-" as in the url:
'keywords2':['-'.join(x.split()) for x in keywords]
Store keywords and votings maybe also interesting:
'keywords3':[{'keyword':k,'votes':v} for k,v in zip(keywords,votes)]
Example
import requests, time
from bs4 import BeautifulSoup
import pandas as pd
keyword_link_list = ['https://www.imdb.com/title/tt7315526/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11723916/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt7844164/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt2034855/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11215178/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt10941266/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt13210836/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt0913137/keywords?ref_=tt_ql_sm'
]
def cook_soup(url):
#do not harm the website add some delay
#time.sleep(2)
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'Referer': 'https://www.google.com/'
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.text,'lxml')
return soup
data = []
for url in keyword_link_list:
soup = cook_soup(url)
keywords = [e.a.text for e in soup.select('[data-item-keyword]')]
votes = [e['data-item-votes'] for e in soup.select('[data-item-votes]')]
data.append({
'url':url,
'keywords1':keywords,
'keywords2':['-'.join(x.split()) for x in keywords],
'keywords3':[{'keyword':k,'votes':v} for k,v in zip(keywords,votes)]
})
print(data)
### pd.DataFrame(data)