I need to transform this monthly data to daily data by using some randomization technique, for example. Here is the dataframe:
library(dplyr)
library(lubridate)
month_year <- c(
"08-2021",
"09-2021",
"10-2021",
"11-2021",
"12-2021"
)
monthly_values_var1 <- c(
598,
532,
736,
956,
780
)
monthly_values_var2 <- c(
18.3179,
62.6415,
11.1033,
30.7443,
74.2076
)
df <- data.frame(month_year, monthly_values_var1, monthly_values_var2)
df
That is the month dataset view:
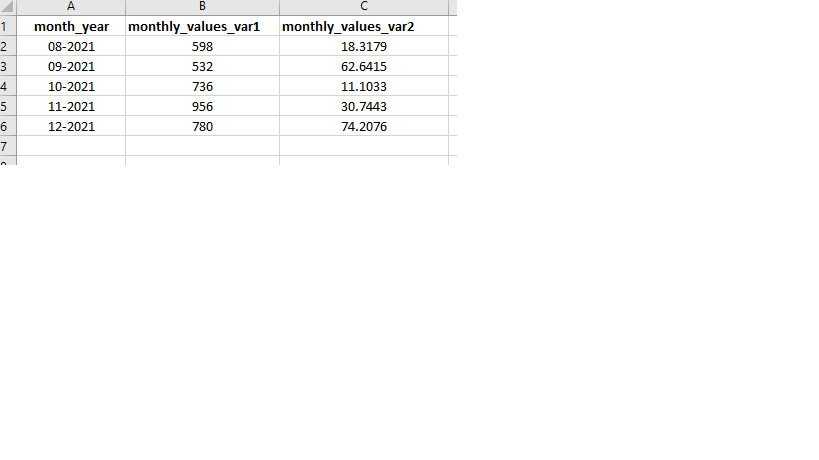
And the expected result of this, is something like this:

How to do it using R ?
CodePudding user response:
Like this perhaps?
df %>%
mutate(mo_start = dmy(paste(1,month_year))) %>%
tidyr::uncount(days_in_month(mo_start), .id = "day") %>%
mutate(date = dmy(paste(day,month_year))) %>%
mutate(across(contains("var"), ~rnorm(n(), mean = .x, sd = 1)))
# A tibble: 153 x 6
month_year monthly_values_var1 monthly_values_var2 mo_start day date
<chr> <dbl> <dbl> <date> <int> <date>
1 08-2021 599. 18.8 2021-08-01 1 2021-08-01
2 08-2021 598. 17.4 2021-08-01 2 2021-08-02
3 08-2021 596. 18.0 2021-08-01 3 2021-08-03
4 08-2021 598. 19.2 2021-08-01 4 2021-08-04
5 08-2021 600. 18.3 2021-08-01 5 2021-08-05
6 08-2021 597. 19.8 2021-08-01 6 2021-08-06
7 08-2021 599. 18.9 2021-08-01 7 2021-08-07
8 08-2021 597. 17.9 2021-08-01 8 2021-08-08
9 08-2021 597. 16.0 2021-08-01 9 2021-08-09
10 08-2021 596. 17.7 2021-08-01 10 2021-08-10
# … with 143 more rows
CodePudding user response:
It is not a one function question.
There are more compact answers, but it is clearer step by step.
First the data:
month_year <- c(
"08-2021",
"09-2021",
"10-2021",
"11-2021",
"12-2021"
)
monthly_values_var1 <- c(
598,
532,
736,
956,
780
)
monthly_values_var2 <- c(
18.3179,
62.6415,
11.1033,
30.7443,
74.2076
)
df <- data.frame(month_year, monthly_values_var1, monthly_values_var2)
df
Some useful libraries:
library(dplyr)
library(lubridate)
library(stringr)
It needs a similar data frame to save new data:
df$month_year <- lubridate::dmy(paste0('01-',df$month_year))
new.df <- df[0,]
Now the code
counter <- 1
for (i in 1:nrow(df)) {
days_month <- lubridate::days_in_month(df[i, 'month_year'])
mean1 <- df[i, 'monthly_values_var1']/days_month
mean2 <- df[i, 'monthly_values_var2']/days_month
for(j in 1:days_month){
if (j < 10) {
value <- str_pad(string = j, width = length(as.character(j)) 1, pad = "0")
} else {
value <- as.character(j)
}
new.df[counter, 'month_year'] <- paste0(lubridate::year(df[i, 'month_year']),'-', lubridate::month(df[i, 'month_year']), '-', value)
new.df[counter, 'monthly_values_var1'] <- rnorm(n = 1, mean = mean1, sd = mean1/3)
new.df[counter, 'monthly_values_var2'] <- rnorm(n = 1, mean = mean2, sd = mean2/3)
counter <- counter 1
}
}
View(new.df)
lubridate::days_in_month() function shows how many days are in a specific month.
rnorm assign a random number with normal distribution. I choose a mean around each data divided days in month, and a standard deviation mean/3.