I`m using pandas dataframe to read .csv format file. I would like to insert rows when specific column values changed from value to other. My data is shown as follow:
Id type
1 car
1 track
2 train
2 plane
3 car
I need to add row that contains Id is empty and type value is number 4 after any change in Id column value. My desired output should like this:
Id type
1 car
1 track
4
2 train
2 plane
4
3 car
How I do this??
CodePudding user response:
You can do this:
df = pd.read_csv('input.csv', sep=";")
Id type
0 1 car
1 1 track
2 2 train
3 2 plane
4 3 car
mask = df['Id'].ne(df['Id'].shift(-1))
df1 = pd.DataFrame('4',index=mask.index[mask] .5, columns=df.columns)
df1['Id'] = df['Id'].replace({'4':' '})
df = pd.concat([df, df1]).sort_index().reset_index(drop=True).iloc[:-1]
which gives:
Id type
0 1.0 car
1 1.0 track
2 NaN 4
3 2.0 train
4 2.0 plane
5 NaN 4
6 3.0 car
CodePudding user response:
You can do:
In [244]: grp = df.groupby('Id')
In [256]: res = pd.DataFrame()
In [257]: for x,y in grp:
...: if y['type'].count() > 1:
...: tmp = y.append(pd.DataFrame({'Id': [''], 'type':[4]}))
...: res = res.append(tmp)
...: else:
...: res = res.append(y)
...:
In [258]: res
Out[258]:
Id type
0 1 car
1 1 track
0 4
2 2 train
3 2 plane
0 4
4 3 car
CodePudding user response:
You could use groupby to split by groups and append the rows in a list comprehension before merging again with contact:
df2 = pd.concat([d.append(pd.Series([None, 4], index=['Id', 'type']), ignore_index=True)
for _,d in df.groupby('Id')], ignore_index=True).iloc[:-1]
If the index is sorted, another option is to find the index of the last item per group and use it to generate the new rows:
# get index of last item per group (except last)
idx = df.index.to_series().groupby(df['Id']).last().values[:-1]
# craft a DataFrame with the new rows
d = pd.DataFrame([[None, 4]]*len(idx), columns=df.columns, index=idx)
# concatenate and reorder
pd.concat([df, d]).sort_index().reset_index(drop=True)
output:
Id type
0 1.0 car
1 1.0 track
2 NaN 4.0
3 2.0 train
4 2.0 plane
5 NaN 4.0
6 3.0 car
CodePudding user response:
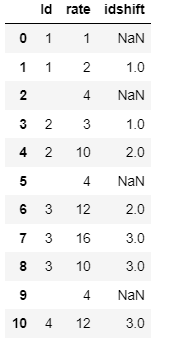
Please find the solution below using index :
###### Create a shift variable to compare index
df['idshift'] = df['Id'].shift(1)
# When shift id does not match id, mean change index
change_index = df.index[df['idshift']!=df['Id']].tolist()
change_index
# Loop through all the change index and insert at index
for i in change_index[1:]:
line = pd.DataFrame({"Id": ' ' , "rate": 4}, index=[(i-1) .5])
df = df.append(line, ignore_index=False)
# finallt sort the index
df = df.sort_index().reset_index(drop=True)
Input Dataframe :
df = pd.DataFrame({'Id': [1,1,2,2,3,3,3,4],'rate':[1,2,3,10,12,16,10,12]})
Ouput Results from the code :