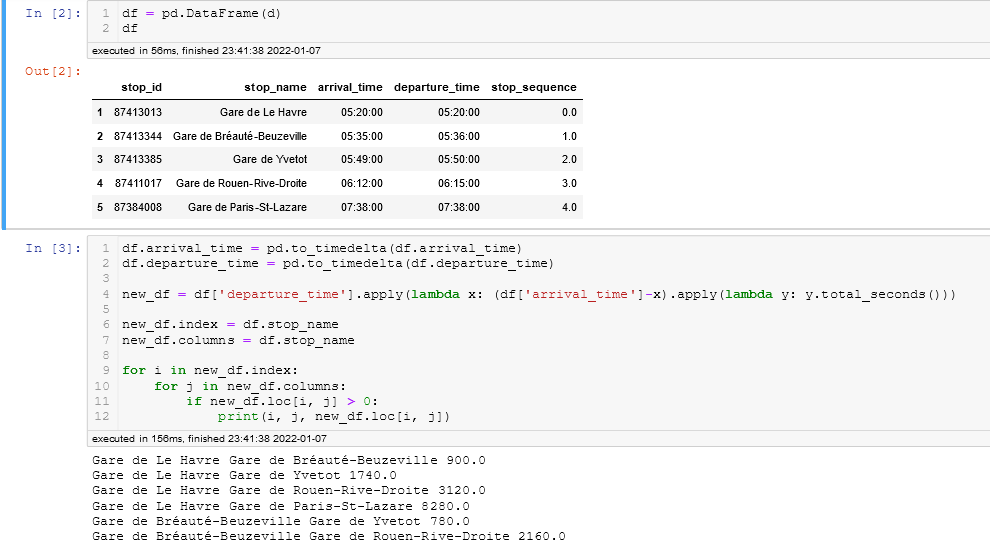
I have a group from a df.groupby that looks like this:
stop_id stop_name arrival_time departure_time stop_sequence
0 87413013 Gare de Le Havre 05:20:00 05:20:00 0.0
1 87413344 Gare de Bréauté-Beuzeville 05:35:00 05:36:00 1.0
2 87413385 Gare de Yvetot 05:49:00 05:50:00 2.0
3 87411017 Gare de Rouen-Rive-Droite 06:12:00 06:15:00 3.0
4 87384008 Gare de Paris-St-Lazare 07:38:00 07:38:00 4.0
I want to loop each row and use "stop_name" as the location of departure and then get the following "stop_name" of the next rows as the location of arrival. Finally I use the below func in order to parse the times and calc the trip duration in seconds.
def timestrToSeconds(timestr):
ftr = [3600,60,1]
return sum([a*b for a,b in zip(ftr, map(int,timestr.split(':')))])
The output is expected to be an array with all possible combinations like below :
result = [
('Gare de Le Havre', 'Gare de Bréauté-Beuzeville', 900),
('Gare de Le Havre', 'Gare de Yvetot', 1740),
('Gare de Le Havre', 'Gare de Rouen-Rive-Droite', 3120),
('Gare de Le Havre', 'Gare de Paris-St-Lazare', 8280),
('Gare de Bréauté-Beuzeville', 'Gare de Yvetot', 780),
('Gare de Bréauté-Beuzeville', 'Gare de Rouen-Rive-Droite', 2160),
('Gare de Bréauté-Beuzeville', 'Gare de Paris-St-Lazare', 7320),
('Gare de Yvetot', 'Gare de Rouen-Rive-Droite', 3120),
('Gare de Yvetot', 'Gare de Paris-St-Lazare', 6480),
('Gare de Rouen-Rive-Droite', 'Gare de Paris-St-Lazare', 4980),
]
I have tried with nested loops but ended up being too abstract for me. Any advice is more than welcome
CodePudding user response:
Until you update your question so this code can be checked with real data, here is one solution:
all_combs=combinations(df['stop_name'].to_list())
results=[]
for c in all_combs:
results.append((*c,abs(df.loc[df['stop_name']==c[0],'arrival_time']-df.loc[df['stop_name']==c[1],'arrival_time'])))
That's assum,ing that arrival_time (or whatever desired column you try to look into) is already in pandas.timedate format. If not, take a look here and convert to timedate: