| Nama | No.ID | Tgl/Waktu | No.PIN | Kode Verifikasi |
|---|---|---|---|---|
| Alif | 100061 | 17/12/2022 07:53:26 | Sidik Jari | |
| Alif | 100061 | 17/12/2022 13:00:25 | Sidik Jari | |
| Alif | 100061 | 19/12/2022 07:54:59 | Sidik Jari | |
| Alif | 100061 | 19/12/2022 16:18:14 | Sidik Jari | |
| Alif | 100061 | 20/12/2022 07:55:54 | Sidik Jari | |
| Alif | 100061 | 20/12/2022 16:16:16 | Sidik Jari | |
| Alif | 100061 | 21/12/2022 07:54:46 | Sidik Jari | |
| Alif | 100061 | 21/12/2022 16:15:41 | Sidik Jari | |
| Alif | 100061 | 22/12/2022 07:55:54 | Sidik Jari | |
| Alif | 100061 | 22/12/2022 16:15:59 | Sidik Jari | |
| Alif | 100061 | 23/12/2022 07:56:26 | Sidik Jari | |
| Alif | 100061 | 23/12/2022 16:16:56 | Sidik Jari | |
| budi | 100063 | 17/12/2022 07:45:28 | Sidik Jari | |
| budi | 100063 | 17/12/2022 13:00:23 | Sidik Jari | |
| budi | 100063 | 19/12/2022 07:39:29 | Sidik Jari | |
| budi | 100063 | 19/12/2022 16:17:37 | Sidik Jari | |
| budi | 100063 | 20/12/2022 13:13:06 | Sidik Jari | |
| budi | 100063 | 20/12/2022 16:16:14 | Sidik Jari | |
| budi | 100063 | 21/12/2022 07:39:54 | Sidik Jari | |
| budi | 100063 | 21/12/2022 16:15:38 | Sidik Jari | |
| budi | 100063 | 22/12/2022 07:39:02 | Sidik Jari | |
| budi | 100063 | 22/12/2022 16:15:55 | Sidik Jari | |
| budi | 100063 | 23/12/2022 07:41:13 | Sidik Jari | |
| budi | 100063 | 23/12/2022 16:16:25 | Sidik Jari |
so from that raw excel file i want to make a app to output the waging system
!pip install xlrd
import pandas as pd
from datetime import time, timedelta
import openpyxl
from google.colab import drive
drive.mount('/content/drive')
# Read the Excel file
path = '/content/drive/MyDrive/Colab Notebooks/Book1.xlsx'
df = pd.read_excel(path)
# Convert the 'Tgl/Waktu' column to datetime format
df['Tgl/Waktu'] = pd.to_datetime(df['Tgl/Waktu'])
# Extract the date and time from the 'Tgl/Waktu' column
df['Date'] = df['Tgl/Waktu'].dt.date
df['Time'] = df['Tgl/Waktu'].dt.time
# Group the data by employee name and date
grouped_df = df.groupby(['Nama', 'Date'])
# Set the overtime threshold to 16:30:00
overtime_threshold = time(hour=16, minute=30)
# Iterate over the grouped data
for (name, date), group in grouped_df:
# Calculate the total work hours and overtime hours for each employee on each day
start_time = group['Time'].min()
end_time = group['Time'].max()
total_hours = (timedelta(hours=end_time.hour, minutes=end_time.minute, seconds=end_time.second) -
timedelta(hours=start_time.hour, minutes=start_time.minute, seconds=start_time.second)).total_seconds() / 3600
if total_hours > 8:
hours_worked = 8
if end_time > overtime_threshold:
overtime_hours = (end_time - overtime_threshold).total_seconds() / 3600
else:
hours_worked = total_hours
overtime_hours = 0
if end_time > overtime_threshold:
overtime_hours = (end_time - overtime_threshold).total_seconds() / 3600
# Calculate the payment for each employee on each day
payment_each_date = 75000 * hours_worked 50000 * overtime_hours
# Add the total work hours, overtime hours, and payment as new columns to the dataframe
df.loc[(df['Nama'] == name) & (df['Date'] == date), 'Hours Worked'] = hours_worked
df.loc[(df['Nama'] == name) & (df['Date'] == date), 'Overtime Hours'] = overtime_hours
df.loc[(df['Nama'] == name) & (df['Date'] == date), 'Payment Each Date'] = payment_each_date
# Print the resulting dataframe
print(df)
# write DataFrame to excel
df.to_excel(excel_writer=r'/content/drive/MyDrive/Colab Notebooks/test.xlsx')
from that code i want to add another column that is total payment, i have an idea to add payment each date thats grouped by name and with different date
how do i do that?
i already try used groupby nama then sum the payment each day but its still error
CodePudding user response:
Updated Answer
If you want to remove duplicate date rows prior to calculating the total payment for each Nama value, then first group by Nama and date, take the max value (min is the same as the two values are equal), group that result by Nama and sum the Payment Each Date values. This produces a new dataframe with the total payment for each Nama, df_total, which can then be joined to the original dataframe to obtain the desired Total Payment column:
df_total = df.groupby(['Nama', 'Date'])['Payment Each Date'].max().groupby('Nama').sum().rename('Total Payment')
df = df.merge(df_total, how='left', on='Nama')
Left join is safer as that will always keep all rows of df just in case.
Updated Output df:
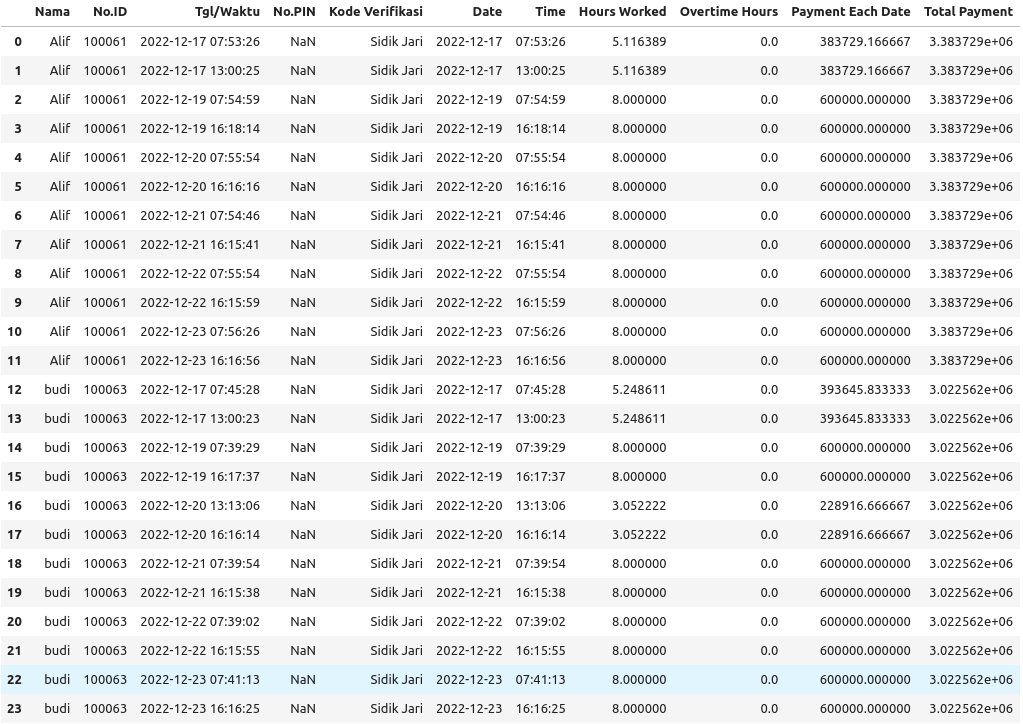
Original Answer
If you just want to sum all the Payment Each Date values in a new column, then add the following line of code after the for loop code block and before the line that prints the df:
df['Total Payment'] = df.groupby('Nama')['Payment Each Date'].transform('sum')
The transform takes care of aligning the indices of the series containing the sum for each Nama value with the original df.
Original Output df:
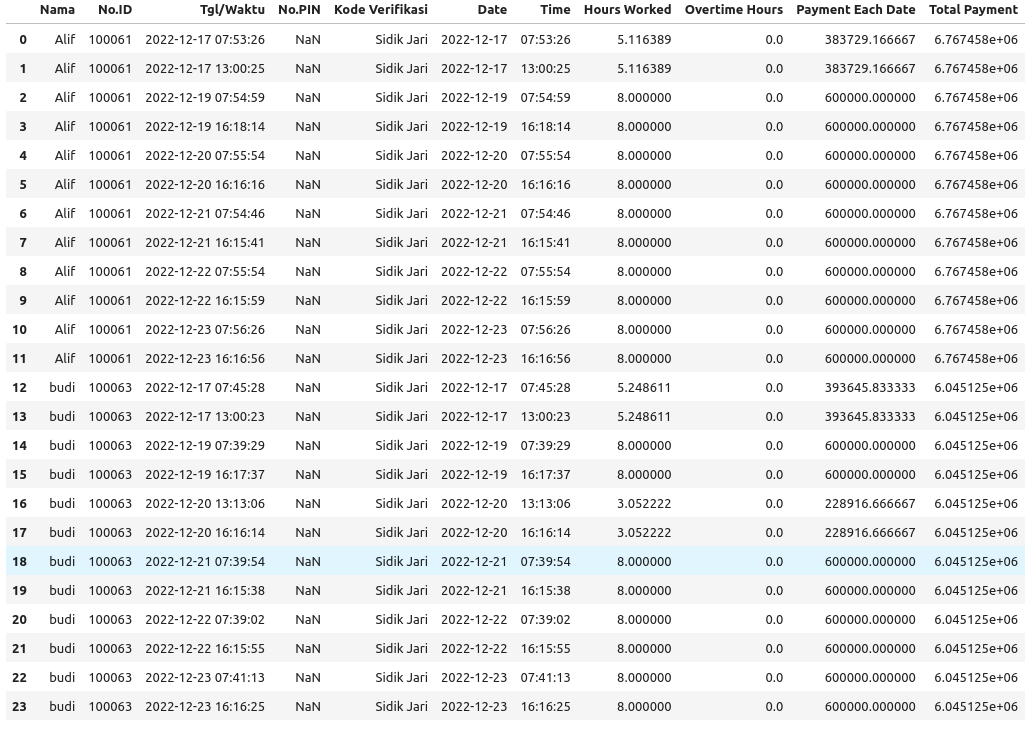
Please take a look at this SO post which has some examples similar to what you are asking about: How do I create a new column from the output of pandas groupby().sum()?