I have a JSON file that looks as such:
library(jsonlite)
test_file <- jsonlite::fromJSON("https://raw.githubusercontent.com/datacfb123/testdata/main/test_file_lp.json")
If you open up test_file in R, you can see it looks as such:

The problem arises from the latestPosts data where some columns contain the data I need, but others don't. If you open up the subdata for username3, you will see two columns titled locationName and locationId, like screen shot below:
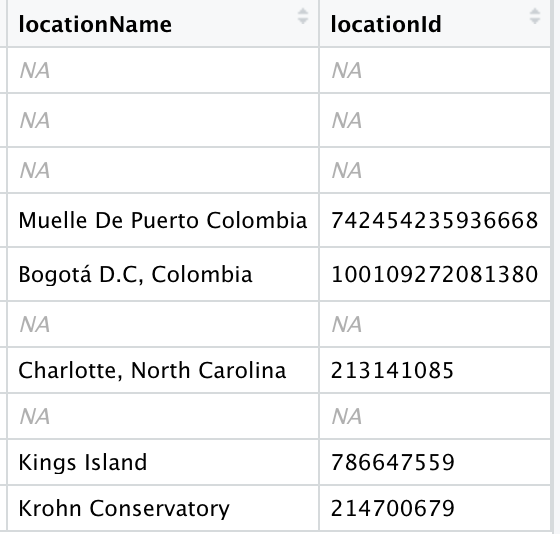
But the nested data for username1 and username2 does not contain those fields, which is fine. username1 has nested data under latestPosts that doesn't have what we need, while username2 has no data.
I am trying to write a script that captures the two location columns from whoever has them, while still keeping the original three columns that are in all of them. So the final dataframe would look like this:
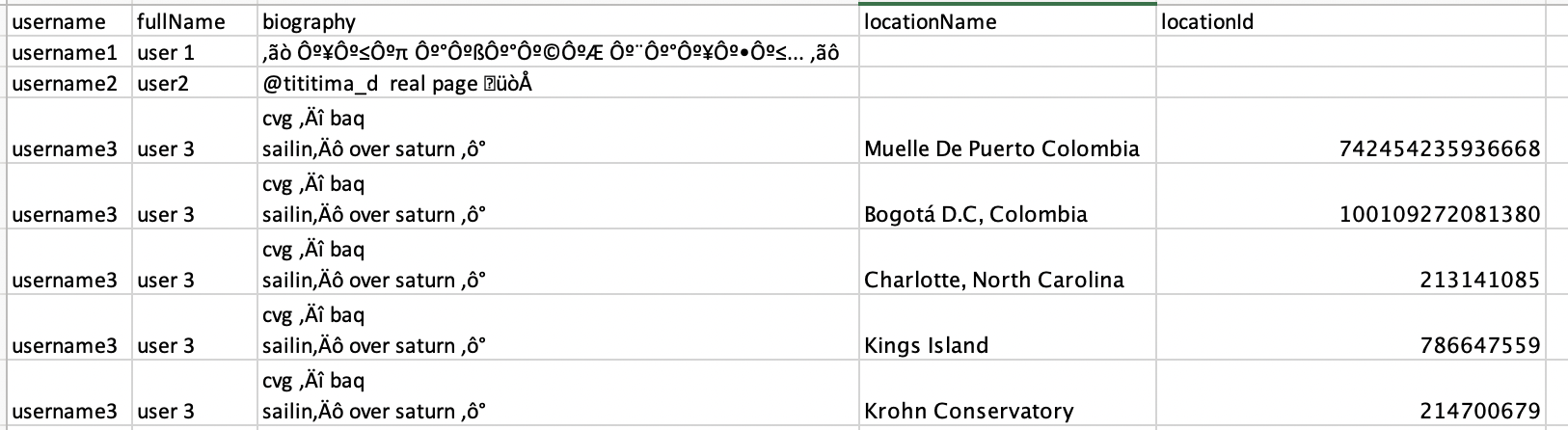
CodePudding user response:
One option is a simple helper function that can be applied using map()
f <- function(lp) {
keys = c("locationName", "locationId")
if(all(keys %in% names(lp))) lp[keys] %>% filter(!is.na(locationName))
else setNames(data.frame(NA_character_, NA_character_),keys)
}
test_file %>%
mutate(latestPosts = map(latestPosts,f)) %>%
unnest(latestPosts)
Output:
# A tibble: 7 × 5
username fullName biography locationName locationId
<chr> <chr> <chr> <chr> <chr>
1 username1 user 1 "⋘ TRY AGAIN LATER... ⋙" NA NA
2 username2 user2 "@tititima_d real page \U0001f601" NA NA
3 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Muelle De Puerto Colombia 742454235936668
4 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Bogotá D.C, Colombia 100109272081380
5 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Charlotte, North Carolina 213141085
6 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Kings Island 786647559
7 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Krohn Conservatory 214700679
CodePudding user response:
You can use tidyr::unnest() to get all columns from all dataframes. Then do a grouped dplyr::summarize() to keep all non-NA values for your columns of interest, or else a single NA row if there are no non-NA values for a group.
library(jsonlite)
library(tidyr)
library(dplyr)
test_file %>%
unnest(latestPosts, keep_empty = TRUE) %>%
group_by(username, fullName, biography) %>%
summarize(across(
c(locationName, locationId),
~ { if (all(is.na(locationName) & is.na(locationId))) NA else .x[!is.na(.x)] },
)) %>%
ungroup()
# A tibble: 7 × 5
username fullName biography locationName locationId
<chr> <chr> <chr> <chr> <chr>
1 username1 user 1 "⋘ TRY AGAIN LATER... ⋙" NA NA
2 username2 user2 "@tititima_d real page \U0001f601" NA NA
3 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Muelle De Puerto Colombia 742454235936668
4 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Bogotá D.C, Colombia 100109272081380
5 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Charlotte, North Carolina 213141085
6 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Kings Island 786647559
7 username3 user 3 "cvg — baq \nsailin’ over saturn ♡" Krohn Conservatory 214700679