I have a sample log file with 1000 lines, that looks like this,
TIME,STATUS
09:00,OK
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:01,OK
09:01,OK
09:01,OK
09:01,PERM
09:01,TEMP
09:01,TEMP
09:02,OK
09:02,TEMP
09:02,TEMP
09:03,OK
09:03,PERM
09:03,PERM
09:03,TEMP
09:03,TEMP
09:04,OK
09:04,PERM
09:04,PERM
09:04,TEMP
09:04,TEMP
09:04,TEMP
09:05,OK
09:05,OK
09:05,OK
09:05,PERM
09:05,TEMP
09:05,TEMP
09:05,TEMP
09:05,TEMP
09:06,OK
09:06,OK
09:06,PERM
09:06,PERM
09:06,PERM
09:06,PERM
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:07,OK
09:07,OK
09:07,TEMP
09:07,TEMP
09:07,TEMP
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,TEMP
09:08,TEMP
09:08,TEMP
09:08,TEMP
09:09,OK
09:09,OK
09:09,OK
09:09,PERM
09:10,OK
09:10,PERM
09:10,PERM
09:10,TEMP
09:11,OK
09:11,OK
09:11,OK
09:11,OK
09:11,PERM
09:11,PERM
09:11,PERM
09:11,PERM
09:11,TEMP
09:11,TEMP
09:11,TEMP
09:12,PERM
09:12,TEMP
09:12,TEMP
09:13,OK
09:13,OK
09:13,OK
09:13,OK
09:13,OK
09:13,PERM
09:13,PERM
09:13,PERM
09:13,TEMP
09:13,TEMP
09:14,OK
09:14,OK
09:14,OK
09:14,PERM
09:14,PERM
09:14,PERM
09:14,PERM
09:14,TEMP
09:16,OK
09:16,OK
09:16,OK
09:16,PERM
09:16,PERM
09:16,TEMP
09:16,TEMP
09:17,OK
09:17,OK
09:17,PERM
09:17,PERM
09:18,OK
09:18,OK
09:18,OK
09:18,OK
09:18,OK
09:18,PERM
09:18,PERM
09:18,TEMP
09:18,TEMP
09:18,TEMP
09:19,OK
09:19,OK
09:19,OK
09:19,OK
09:19,OK
09:19,PERM
09:20,OK
09:20,OK
09:20,PERM
09:20,PERM
09:20,TEMP
09:20,TEMP
09:21,OK
09:21,OK
09:21,OK
09:21,PERM
09:21,TEMP
09:22,OK
09:22,OK
09:22,PERM
09:22,PERM
09:22,TEMP
09:22,TEMP
09:23,OK
09:23,PERM
09:23,PERM
09:23,PERM
09:23,TEMP
09:23,TEMP
09:23,TEMP
09:24,PERM
09:24,PERM
09:24,PERM
09:25,OK
09:25,OK
09:25,PERM
09:25,TEMP
09:26,OK
09:26,OK
09:26,OK
09:26,OK
09:26,OK
09:26,PERM
09:26,TEMP
09:27,OK
09:27,OK
09:27,OK
09:27,PERM
09:27,PERM
09:27,TEMP
09:27,TEMP
09:27,TEMP
09:28,PERM
09:28,PERM
09:28,PERM
09:28,PERM
09:29,OK
...
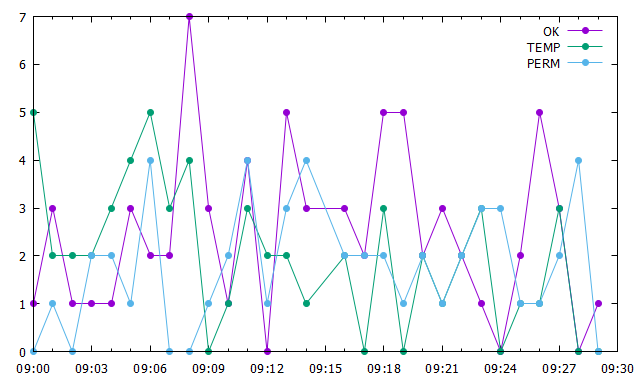
while the final file will have 10K lines in the same time frame. I need to create a graph to show number of statuses per minute for TEMP, PERM and OK. So I would like to use a line for the status (TEMP, PERM and OK), plot time on the X axis, and frequency of occurrence on the Y axis.
I installed Gnuplot only 2 days ago on my Ubuntu 20.04.4 LTS from the standard repo:
bi@green:bin$ apt list gnuplot* 2>/dev/null | grep installed
gnuplot-data/focal,focal,now 5.2.8 dfsg1-2 all [installed,automatic]
gnuplot-qt/focal,now 5.2.8 dfsg1-2 amd64 [installed,automatic]
gnuplot/focal,focal,now 5.2.8 dfsg1-2 all [installed]
and so far I haven't managed more than this,
#!/bin/bash
x=logoutcol
cat $x
gnuplot -p <<-EOF
#set ytics scale 0
#set yzeroaxis
reset
set format x "%H:%M" time
set xdata time
set yrange [0:*]
set ylabel "Occurences"
set ytics 2
#set margin at screen 0.95
binwidth=60
bin(val) = binwidth * floor(val/binwidth)
set boxwidth binwidth
set datafile separator ","
set term png
set output "$x.png"
plot "$x" using (bin(timecolumn(1,"%H%M"))):(2) smooth freq with boxes
EOF
shotwell $x.png
rm $x.png
which produces this:
Any help will be much appreciated.
CodePudding user response:
I am pretty sure that there was an almost identical question here on SO, however, it seems I can't find it maybe due to my incapability of finding the right keywords for SO's search function.
The key point is the boolean expression (strcol(2) eq word(myKeys,i)) together with smooth frequency. If the value of the second column is identical to your keyword the expression results in 1, and 0 otherwise.
You don't need bins like in creating other histograms because you want a bin of 1 minute (and your time resolution is already 1 minute).
Check the following example as starting point for further optimization.
Script:
### count occurrences of keywords
reset session
$Data <<EOD
# TIME,STATUS
09:00,OK
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:00,TEMP
09:01,OK
09:01,OK
09:01,OK
09:01,PERM
09:01,TEMP
09:01,TEMP
09:02,OK
09:02,TEMP
09:02,TEMP
09:03,OK
09:03,PERM
09:03,PERM
09:03,TEMP
09:03,TEMP
09:04,OK
09:04,PERM
09:04,PERM
09:04,TEMP
09:04,TEMP
09:04,TEMP
09:05,OK
09:05,OK
09:05,OK
09:05,PERM
09:05,TEMP
09:05,TEMP
09:05,TEMP
09:05,TEMP
09:06,OK
09:06,OK
09:06,PERM
09:06,PERM
09:06,PERM
09:06,PERM
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:06,TEMP
09:07,OK
09:07,OK
09:07,TEMP
09:07,TEMP
09:07,TEMP
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,OK
09:08,TEMP
09:08,TEMP
09:08,TEMP
09:08,TEMP
09:09,OK
09:09,OK
09:09,OK
09:09,PERM
09:10,OK
09:10,PERM
09:10,PERM
09:10,TEMP
09:11,OK
09:11,OK
09:11,OK
09:11,OK
09:11,PERM
09:11,PERM
09:11,PERM
09:11,PERM
09:11,TEMP
09:11,TEMP
09:11,TEMP
09:12,PERM
09:12,TEMP
09:12,TEMP
09:13,OK
09:13,OK
09:13,OK
09:13,OK
09:13,OK
09:13,PERM
09:13,PERM
09:13,PERM
09:13,TEMP
09:13,TEMP
09:14,OK
09:14,OK
09:14,OK
09:14,PERM
09:14,PERM
09:14,PERM
09:14,PERM
09:14,TEMP
09:16,OK
09:16,OK
09:16,OK
09:16,PERM
09:16,PERM
09:16,TEMP
09:16,TEMP
09:17,OK
09:17,OK
09:17,PERM
09:17,PERM
09:18,OK
09:18,OK
09:18,OK
09:18,OK
09:18,OK
09:18,PERM
09:18,PERM
09:18,TEMP
09:18,TEMP
09:18,TEMP
09:19,OK
09:19,OK
09:19,OK
09:19,OK
09:19,OK
09:19,PERM
09:20,OK
09:20,OK
09:20,PERM
09:20,PERM
09:20,TEMP
09:20,TEMP
09:21,OK
09:21,OK
09:21,OK
09:21,PERM
09:21,TEMP
09:22,OK
09:22,OK
09:22,PERM
09:22,PERM
09:22,TEMP
09:22,TEMP
09:23,OK
09:23,PERM
09:23,PERM
09:23,PERM
09:23,TEMP
09:23,TEMP
09:23,TEMP
09:24,PERM
09:24,PERM
09:24,PERM
09:25,OK
09:25,OK
09:25,PERM
09:25,TEMP
09:26,OK
09:26,OK
09:26,OK
09:26,OK
09:26,OK
09:26,PERM
09:26,TEMP
09:27,OK
09:27,OK
09:27,OK
09:27,PERM
09:27,PERM
09:27,TEMP
09:27,TEMP
09:27,TEMP
09:28,PERM
09:28,PERM
09:28,PERM
09:28,PERM
09:29,OK
EOD
set datafile separator comma
myKeys = "OK TEMP PERM"
myKey(i) = word(myKeys,i)
myTimeFmt = "%H:%M"
set format x myTimeFmt timedate
plot for [i=1:words(myKeys)] $Data u (timecolumn(1,myTimeFmt)):(strcol(2) eq word(myKeys,i)) smooth freq w lp pt 7 ti word(myKeys,i)
### end of script
Result: