Currently I'm using pandas and numpy to play around with a data set on rain measurements in India, however I'm stumped on trying to create a particular column. Currently my data set looks like this:
| SUBDIVISION | JAN | FEB | MAR | APR | MAY |
|---|---|---|---|---|---|
| Andaman & Nicobar Islands | 50 | 70 | 90 | 250 | 430 |
| Arunachal Pradesh | 46 | 90 | 151 | 265 | 356 |
| Assam & Meghalaya | 16 | 31 | 79 | 505 | 340 |
| Bihar | 13 | 14 | 100 | 16 | 53 |
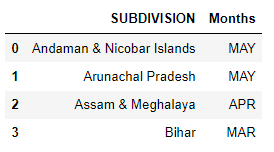
What I want is to replace all the columns that have the months with a single column "Months", and I want this column to contain the name of the month that has the most amount of rain, so for example it would look like this:
| SUBDIVISION | Months |
|---|---|
| Andaman & Nicobar Islands | MAY |
| Arunachal Pradesh | MAY |
| Assam & Meghalaya | APR |
| Bihar | MAR |
My data set is much larger than this so trying to manually input all of the data would not be worth it. So, I'm hoping there's a way to do what I'm wanting in Python
CodePudding user response:
Use
# get column name of max values in month columns
df.set_index('SUBDIVISION').idxmax(1).reset_index(name='Months')
CodePudding user response:
You can use pd.melt to transform your data first.
import pandas as pd
df = pd.DataFrame({
'subdivision': ['a','b'],
'jun': [1,2],
'july': [2,1]
})
df = pd.melt(df, id_vars=['subdivision'], var_name='month', value_name='rain')
df
df:
| subdivision | month | rain |
|---|---|---|
| a | jun | 1 |
| b | jun | 2 |
| a | july | 2 |
| b | july | 1 |
Then, sort value with rain value and drop_duplicates subdivision for keeping only the row having max rain value in each subdivision
df = df.sort_values('rain', ascending=False).drop_duplicates(['subdivision'])
Output:
| subdivision | month | rain |
|---|---|---|
| b | jun | 2 |
| a | july | 2 |