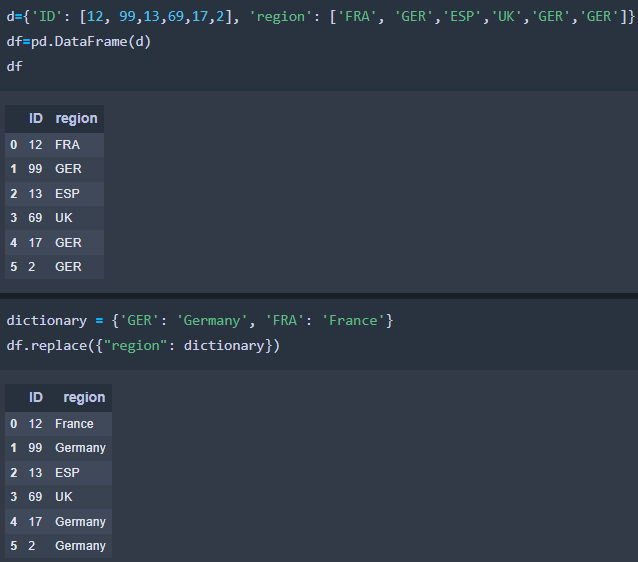
Let it be the following Python Pandas DataFrame.
| ID | region |
|---|---|
| 12 | FRA |
| 99 | GER |
| 13 | ESP |
| 69 | UK |
| 17 | GER |
| 02 | GER |
Using the next code:
dictionary = {'GER': 'Germany', 'FRA': 'France'}
df['region'] = df['region'].map(dictionary)
I get the following result:
| ID | region |
|---|---|
| 12 | France |
| 99 | Germany |
| 13 | NaN |
| 69 | NaN |
| 17 | Germany |
| 02 | Germany |
My idea is that the values that do not appear in the dictionary, keep their previous values.
| ID | region |
|---|---|
| 12 | France |
| 99 | Germany |
| 13 | ESP |
| 69 | UK |
| 17 | Germany |
| 02 | Germany |
How could I do this? Thank you in advance.
CodePudding user response:
I think what you want is that :
df.replace({"region": dictionary})
CodePudding user response:
Use fillna (or combine_first):
df['region'] = df['region'].map(dictionary).fillna(df['region'])
or take advantage of the get method to set the value as default:
df['region'] = df['region'].map(lambda x: dictionary.get(x, x))
output:
ID region
0 12 France
1 99 Germany
2 13 ESP
3 69 UK
4 17 Germany
5 2 Germany