I have a csv with a line break that I import to R using the read.csv feature and I want to identify the unique values in one of the columns. For example my example.csv file looks like this:
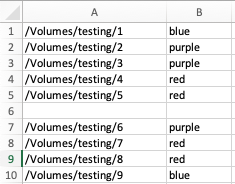
I believe I can use unique after I delete the empty row which I do like this:
df <- read.csv(file = "example.csv",header = FALSE)
colnames(df)[1:2] <- c("path","group")
df <- df[!(df$path=="" | df$group==""), ]
unique_groups <- unique(df$group)
However, unique_groups (despite only having 3 different groups), turns out to be a factor with 4 levels, my 3 different groups and then blank or "".
I have figured out that if I save df as a csv right before the unique_groups step and the read back in that csv, it works fine and then unique_groups is a factor with 3 levels, but I'm wondering if there is a more efficient way to do this? Am I doing something wrong with the initial import or how I remove the blank row?
Any help is appreciated - thanks!
CodePudding user response:
Turns out when I imported my csv, it was classifying column B as a factor which was causing my problems. So now I just import it as a character class and that has resolved my issue, like so:
df <- read.csv(file = "example.csv",header = FALSE, colClasses = c("character","character"))