Say I have two 2d arrays:
aa = np.array([[1,2],[3,4],[9,10],[48,59]])
bb = np.array([[1,2],[9,10]])
array aa is my ideal array and bb is what I have recorded. I want to find out what rows bb is missing compared to aa. I can do this by looping through the rows but as my dataset is approximately 5Gb I want to know if there is a pythonic way of doing this to minimize run time. It would be preferable to carry out this operation as a numpy array but it doesn't HAVE to be that way if there is a better option.
Any help is appreciated. Thanks
CodePudding user response:
Try this:
bb_missing = aa[~np.all(aa==bb[:, None], axis=2).any(axis=0)]
Output:
>>> bb_missing
array([[ 3, 4],
[48, 59]])
CodePudding user response:
The main step is to find boolean indices of aa that tells if items in aa are present in bb. For example, if:
aa = np.array([[1,2],[3,4],[9,10],[48,59]])
bb = np.array([[1,2],[9,10]])
then we should get:
idx
>>> array([ True, False, True, False])
And we could use later:
aa[~idx]
>>>
array([[ 3, 4],
[48, 59]])
Since aa[~idx] is relatively fast, I'll try to review all the ways to find idx. They divide between two groups: the way of searching the data (np.isin, np.searchsort, etc.) and the way that data could be made 1-dimensional.
The way of reduction
Way 1. Make arrays aa and bb contiguous then call np.isin on their views:
def _view1D(a, b): # a, b are arrays
a = np.ascontiguousarray(a, dtype=np.uint32)
b = np.ascontiguousarray(b, dtype=np.uint32)
uint32_dt = np.dtype([('', np.uint32)]*2)
return a.view(uint32_dt).ravel(), b.view(uint32_dt).ravel()
A, B = _view1D(aa, bb)
idx = np.isin(A, B)
Way 2.
Reduce dimensionality of aa and bb then call np.isin on resulting arrays:
def numpy_dimreduce(arr, M):
return np.ravel_multi_index(arr.T, M, order='F')
M = aa.max(axis=0) 1
idx = np.isin(numpy_dimreduce(aa, M), numpy_dimreduce(bb, M))
Way 3. Improve performance of dimensionality reduction significantly using numba:
@njit(parallel=True)
def _numba_dot(arr, dimshape, len_arr, len_dimshape, su):
for i in prange(len_arr):
for j in range(len_dimshape):
su[i] = su[i] arr[i][j] * dimshape[j]
def numba_dimreduce(arr, M, dtype=np.int64):
'''not safe if allocation is exceeded'''
dimshape = np.cumprod(np.insert(M[:-1], 0, 1))
su = np.zeros(len(arr), dtype=dtype)
_numba_dot(arr, dimshape, len(arr), len(dimshape), su)
return su
M = aa.max(axis=0) 1
idx = np.isin(numba_dimreduce(aa, M), numba_dimreduce(bb, M))
The way of sorting
Way 1.
Use np.isinlike in previous solutions
Way 2.
Use np.searchsorted:
def searchsort(A, B):
sidx = A.argsort()
out = np.zeros(len(A), dtype=bool)
s = np.searchsorted(A, B, sorter=sidx)
out[sidx[s]] = True
return out
Conclusion
In conclusion, the general pattern of finding idx looks like this:
def isin2D(a, b, view=_view1D, search=np.isin):
# choose your optional view and search
A, B = view(a), view(b)
idx = search(A, B)
return idx
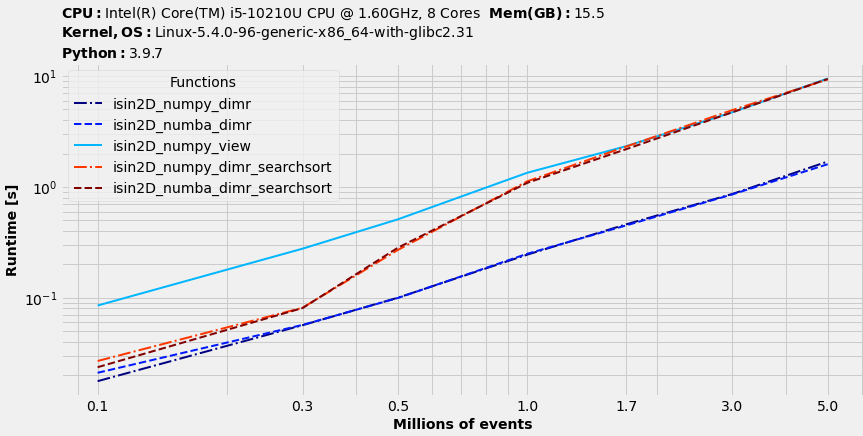
Actually, neither ndarray.views nor np.searchsorted helps to save time. The best option is to combine dimensionality reduction with np.isin.
Performance
Now let's time it using benchit package to illustrate what's winning
import numpy as np
from numba import njit, prange
import benchit
%matplotlib inline
benchit.setparams(rep=3)
sizes = [100000, 300000, 500000, 1000000, 1700000, 3000000, 5000000]#, 10000000, 30000000]
N = sizes[-1]
aa = np.random.randint(0, 1000000, size=(N, 2))
r = np.random.randint(0, 2, size=N).astype(bool)
M = aa.max(axis=0) 1
def _view1D(arr, dtype=np.uint32):
a = np.ascontiguousarray(arr, dtype=dtype)
dt = np.dtype([('', dtype)]*2)
return a.view(dt).ravel()
def _numpy_dimreduce(arr, M):
return np.ravel_multi_index(arr.T, M, order='C')
@njit(parallel=True)
def _numba_dot(arr, dimshape, len_arr, len_dimshape, su):
for i in prange(len_arr):
for j in range(len_dimshape):
su[i] = su[i] arr[i][j] * dimshape[j]
def _numba_dimreduce(arr, M, dtype=np.int64):
'''not safe if allocation is exceeded'''
dimshape = np.cumprod(np.insert(M[:-1], 0, 1))
su = np.zeros(len(arr), dtype=dtype)
_numba_dot(arr, dimshape, len(arr), len(dimshape), su)
return su
def isin2D(a, b, view=_view1D, search=np.isin):
A, B = view(a), view(b)
idx = search(A, B)
return idx
def searchsort(A, B):
sidx = A.argsort()
out = np.zeros(len(A), dtype=bool)
s = np.searchsorted(A, B, sorter=sidx)
out[sidx[s]] = True
return out
def isin2D_numpy_dimr(a, b, M=M): return isin2D(a, b, view=lambda arr, M=M: _numpy_dimreduce(arr, M))
def isin2D_numba_dimr(a, b, M=M): return isin2D(a, b, view=lambda arr, M=M: _numba_dimreduce(arr, M))
def isin2D_numpy_view(a, b): return isin2D(a, b)
def isin2D_numpy_dimr_searchsort(a, b, M=M): return isin2D(a, b, view=lambda arr, M=M: _numpy_dimreduce(arr, M), search=searchsort)
def isin2D_numba_dimr_searchsort(a, b, M=M): return isin2D(a, b, view=lambda arr, M=M: _numba_dimreduce(arr[:, ::-1], M[::-1]), search=searchsort)
fns = [isin2D_numpy_dimr, isin2D_numba_dimr, isin2D_numpy_view, isin2D_numpy_dimr_searchsort, isin2D_numba_dimr_searchsort]
in_ = {s/1000000: (aa[:s], aa[:s][r[:s]]) for s in sizes}
t = benchit.timings(fns, in_, multivar=True, input_name='Millions of events')
t.plot(logx=True, figsize=(12, 6), fontsize=14)