I am doing a project on movies data.
The sample dataset looks like :
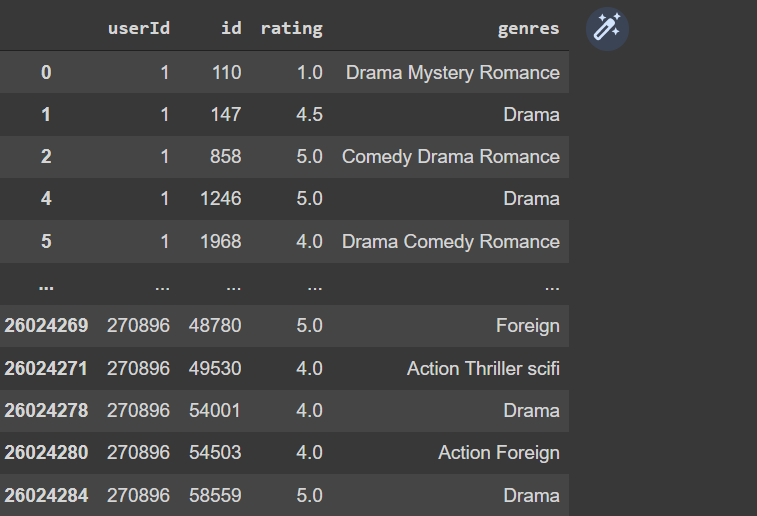
The column genres have 21 unique values.
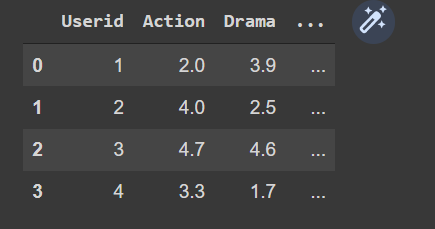
I want to create a new table/dataframe so that the table will contains the average ratings for the each genres for every user, like
I got the list of genres using the code below:
def split(sent):
return (sent.split())
new_genres=set()
for i in range(len(genres)):
a=split(genres[i])
for g in a:
new_genres.add(g)
new_genres
CodePudding user response:
Setup:
In [905]: df = pd.DataFrame({'userID':[1,2,3,3,2], 'id':[110, 147, 858, 1246, 1968], 'rating':[1.0, 4.5, 5.0, 5.0, 4.0], 'genres':['Drama Mystery Romance', 'Drama', 'Comedy Drama Romance', 'Drama', 'Drama Comedy Romance']}
...: )
In [906]: df
Out[906]:
userID id rating genres
0 1 110 1.0 Drama Mystery Romance
1 2 147 4.5 Drama
2 3 858 5.0 Comedy Drama Romance
3 3 1246 5.0 Drama
4 2 1968 4.0 Drama Comedy Romance
Use Series.str.split, df.explode with df.pivot_table:
In [907]: df['genres'] = df['genres'].str.split()
In [910]: res = df.explode('genres').pivot_table(index='userID', columns='genres', values='rating', aggfunc='mean').fillna(0, downcast='infer')
In [911]: res
Out[911]:
genres Comedy Drama Mystery Romance
userID
1 0 1.00 1 1
2 4 4.25 0 4
3 5 5.00 0 5
CodePudding user response:
We can start by using the assign method to get each genre in rows like so :
>>> df = df.assign(genre=df['genres'].str.split(' ')).explode('genre')
>>> df
userId id rating genres genre
0 1 110 1.0 Drama Mystery Romance Drama
0 1 110 1.0 Drama Mystery Romance Mystery
0 1 110 1.0 Drama Mystery Romance Romance
1 1 147 4.5 Drama Drama
2 1 858 5.0 Comedy Drama Romance Comedy
2 1 858 5.0 Comedy Drama Romance Drama
2 1 858 5.0 Comedy Drama Romance Romance
3 1 1246 5.0 Drama Drama
4 1 1968 4.0 Drama Comedy Romance Drama
4 1 1968 4.0 Drama Comedy Romance Comedy
4 1 1968 4.0 Drama Comedy Romance Romance
5 270896 48780 5.0 Forein Forein
6 270896 49530 4.0 Action Thriller Scifi Action
6 270896 49530 4.0 Action Thriller Scifi Thriller
6 270896 49530 4.0 Action Thriller Scifi Scifi
7 270896 54001 4.0 Drama Drama
8 270896 54503 4.0 Action Forein Action
8 270896 54503 4.0 Action Forein Forein
9 270896 58559 5.0 Drama Drama
Then we groupby userId and genre to get the mean of rating:
>>> df_grouped = df.groupby(['userId', 'genre'])['rating'].mean()
>>> df_grouped
userId genre
1 Comedy 4.500000
Drama 3.900000
Mystery 1.000000
Romance 3.333333
270896 Action 4.000000
Drama 4.500000
Forein 4.500000
Scifi 4.000000
Thriller 4.000000
Name: rating, dtype: float64
To finish, we can use unstack to get the expected result :
>>> df_grouped.unstack(level=-1).fillna(0)
genre Action Comedy Drama Forein Mystery Romance Scifi Thriller
userId
1 0.0 4.5 3.9 0.0 1.0 3.333333 0.0 0.0
270896 4.0 0.0 4.5 4.5 0.0 0.000000 4.0 4.0