I am trying to create a pl/pgsql equivalent to the pandas 'ffill' function. The function should forward fill null values. In the example I can do a forward fill but I get errors when I try to create a function from my procedure. The function seems to reflect exactly the procedure but I get a syntax error at the portion ... as $1.
Why? What should I be reading to clarify?
-- Forward fill experiment
DROP TABLE IF EXISTS example;
create temporary table example(id int, str text, val integer);
insert into example values
(1, 'a', null),
(1, null, 1),
(2, 'b', 2),
(2,null ,null );
select * from example
select (case
when str is null
then lag(str,1) over (order by id)
else str
end) as str,
(case
when val is null
then lag(val,1) over (order by id)
else val
end) as val
from example
-- Forward fill function
create or replace function ffill(text, text, text) -- takes column to fill, the table, and the ordering column
returns text as $$
begin
select (case
when $1 is null
then lag($1 ,1) over (order by $3)
else $1
end) as $1
from $2;
end;
$$ LANGUAGE plpgsql;
Update 1: I did some additional experimenting taking a different approach. The code is below. It uses the same example table as above.
CREATE OR REPLACE FUNCTION GapFillInternal(
s anyelement,
v anyelement) RETURNS anyelement AS
$$
declare
temp alias for $0 ;
begin
RAISE NOTICE 's= %, v= %', s, v;
if v is null and s notnull then
temp := s;
elsif s is null and v notnull then
temp := v;
elsif s notnull and v notnull then
temp := v;
else
temp := null;
end if;
RAISE NOTICE 'temp= %', temp;
return temp;
END;
$$ LANGUAGE PLPGSQL;
CREATE AGGREGATE GapFill(anyelement) (
SFUNC=GapFillInternal,
STYPE=anyelement
);
select id, str, val, GapFill(val) OVER (ORDER by id) as valx
from example;
The resulting table is this:
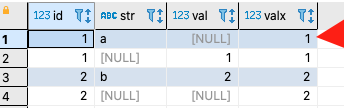
I don't understand where the '1' in the first row of valx column comes from. From the raise notice output it should be Null and that seems a correct expectation from the 
CodePudding user response:
The workaround I needed is to add a column that reflected the order of the rows. The table creation is the same but I add a row column.
DROP TABLE IF EXISTS example;
create temporary table example(id int, str text, val integer);
insert into example values
(1, 'a', null),
(1, null, 3),
(2, 'b', 4),
(2,null ,null );
alter table example add row_num serial; ----- add this
In my real application as in the example, I don't have a timestamp but I know that the order of the rows as they are provided is 'the truth', so I add a 'row_num' column. So now the function:
CREATE OR REPLACE FUNCTION GapFillInternal(
s anyelement,
v anyelement) RETURNS anyelement AS
$$
declare
temp alias for $0 ;
begin
RAISE NOTICE 's= %, v= %', s, v;
if v is null and s notnull then
temp := s;
elsif s is null and v notnull then
temp := v;
elsif s notnull and v notnull then
temp := v;
else
temp := null;
end if;
RAISE NOTICE 'temp= %', temp;
return temp;
END;
$$ LANGUAGE PLPGSQL;
CREATE AGGREGATE GapFill(anyelement) (
SFUNC=GapFillInternal,
STYPE=anyelement
);
select id, str, GapFill(str) OVER (order by row_num) as strx, val, GapFill(val) OVER (order by row_num) as valx
from example;
Gives:
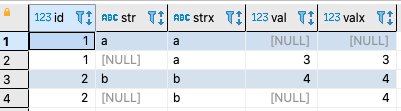
CodePudding user response:
Correct call
Seems like your displayed query is incorrect, and the test case is just to reduced to show it.
Assuming you want to "forward fill" partitioned by id, you'll have to say so:
SELECT row_num, id
, str, gapfill(str) OVER w AS strx
, val, gapfill(val) OVER w AS valx
FROM example
WINDOW w AS (PARTITION BY id ORDER BY row_num); -- !
The WINDOW clause is just a syntactical convenience to avoid spelling out the same window frame repeatedly. The important part is the added PARTITION clause.
Simpler function
Much simpler, actually:
CREATE OR REPLACE FUNCTION GapFillInternal(s anyelement, v anyelement)
RETURNS anyelement
LANGUAGE plpgsql AS
$func$
BEGIN
RETURN COALESCE(v, s); -- that's all!
END
$func$;
CREATE AGGREGATE gap_fill(anyelement) (
SFUNC = gap_fill_internal,
STYPE = anyelement
);
Slightly faster in a quick test.
Standard SQL
Without custom function:
SELECT row_num, id
, str, first_value(str) OVER (PARTITION BY id, ct_str ORDER BY row_num) AS strx
, val, first_value(val) OVER (PARTITION BY id, ct_val ORDER BY row_num) AS valx
FROM (
SELECT *, count(str) OVER w AS ct_str, count(val) OVER w AS ct_val
FROM example
WINDOW w AS (PARTITION BY id ORDER BY row_num)
) sub;
The query becomes more complex with a subquery. Performance is similar. Slightly slower in a quick test.
More explanation in these related answers:
- Carry over long sequence of missing values with Postgres
- Retrieve last known value for each column of a row
- SQL group table by "leading rows" without pl/sql
db<>fiddle here - showing all with extended test case